강화학습 알고리즘: PPO(Proximal Policy Optimization)
이 포스팅은 ‘강화학습 알고리즘‘에 대한 내용을 담고 있습니다.
자료 출처: 단단한 강화학습, Reinforcement Learning An Introduction , 2nd edition. 리처드 서튼, 앤드류 바트로, 김성우(옮긴이), https://www.youtube.com/watch?v=Ukloo2xtayQ
PPO(Proximal Policy Optimization)
TRPO는 신뢰 구역이라는 아이디어를 통해 높은 성능을 달성할 수 있었지만, 구현 난이도가 너무 높고 계산량이 너무 크다는 단점이 있었습니다.
\[\max_{\theta} L^{TRPO}(\theta) = E[\frac{\pi_\theta(a|s)}{\pi_{\theta_{old}}(a|s)}A_{\theta_{old}}(s, a)] \space\space\space subject \space to \space \space\space E_{s\sim\rho_{\theta_{old}}}[D_{KL}(\pi_{old}(\cdot | s) || \pi(\cdot | s))] \leq \delta\]계산량과 난이도의 원인은 TRPO에서 제시했던 신뢰 구역에 있습니다. 신뢰 구역을 의미하는 제약식의 KL Divergence를 구할 때 Hessian 행렬을 사용하기 때문에 큰 계산량을 필요로 합니다. 그런데 신뢰 구역이 알고리즘에게 주는 이득이 무엇인지 생각해보면, 신뢰 구역은 결국 현재 정책과 다음 정책 사이의 괴리가 커지지 않도록 제한하는 역할을 합니다. 만약에 위의 식에서 제약식이 없었다고 한다면, 평균적으로 좋은 행동(Advantage가 큰 행동)을 선택할 확률을 무조건적으로 높이는 방향으로 업데이트가 수행될 것입니다. 이렇게 업데이트를 하면 목적함수의 값은 올라가겠지만, 결과적으로는 좋지 못한 정책에 도달할 가능성이 높기 때문에 이를 방지하기 위해 신뢰 구역을 TRPO에서 도입했습니다.
그런데 신뢰 구역이 현재 정책과 새로운 정책 사이 분포의 차이를 제한하는 역할을 수행하는 거라면, 그걸 꼭 엄청난 계산량을 필요로 하는 KL-Divergence를 사용할 필요는 없어보입니다. 단순히 Clipping을 통해서도 현재 정책과 새로운 정책 사이의 분포 변화를 조절할 수 있을 것입니다. 이렇게 TRPO에서 제약식을 사용하지 않고 좀 더 단순한 방식으로 현재 정책과 새로운 정책 사이의 분포 변화를 조절한 알고리즘이 바로 PPO(Proximal Policy Optimization)입니다.
Clipped Surrogate Objective Function
\[\max_\theta L^{CLIP}(\theta) = E[\min (r(\theta)\space A_{\theta_{old}}(s, a), \space clip(r(\theta),\space 1-\epsilon, \space1 + \epsilon)\space A_{\theta_{old}}(s, a))]\] \[r(\theta) = \frac{\pi_\theta(a|s)}{\pi_{\theta_{old}}(a|s)}\]$r(\theta)$는 현재 정책과 다음 정책 사이의 차이라고 생각할 수 있는데, 이 값의 크기를 제약식이 아니라 $clip$ 함수를 사용해 조절합니다. 그런데 TRPO의 목적함수가 그냥 정해진게 아니라 $\eta(\theta)$의 하한이 되도록 정해진 것이었는데, 위의 $L^{CLIP}(\theta)$ 도 하한을 만족하는지 확인할 필요가 있습니다.
\[\min (r(\theta)\space A_{\theta_{old}}(s, a), \space clip(r(\theta),\space 1-\epsilon, \space1 + \epsilon)\space A_{\theta_{old}}(s, a))\]위 식에서 $\min$ 함수의 입력으로 기존 목적함수인 $r(\theta)\space A_{\theta_{old}}(s, a)$가 들어갑니다. 따라서 $L^{CLIP}(\theta)$은 $L^{TRPO}(\theta)$보다 작을 수밖에 없으므로 하한 조건을 만족하고 MM 알고리즘을 통해 최적화를 수행할 수 있겠습니다.
Practical Implementation
\[L^{CLIP + VF + S}(\theta) = E[L^{CLIP}(\theta) - c_1L^{VF}(\theta) + c_2S[\pi_\theta](s) ]\]실제로는 조금 더 복잡한 목적함수를 사용합니다. 알고리즘의 최적화 대상으로 Advantage 함수를 사용한다면, Q함수와 V함수를 따로 가지고 있어야 합니다. 그런데 Q함수와 V함수가 파라미터를 서로 공유하는 이따금씩 존재합니다. 이 경우에 V함수에 대한 error-term을 넣어주면 학습에 도움이 됩니다. 이게 위 식의 $L^{VF}(\theta)$의 의미입니다.
이어서 원래 식 자체에는 탐험을 이끌 수 있는 요소가 크게 없기 때문에 알고리즘이 탐험을 할 수 있도록 엔트로피 보너스인 $S$를 뒤에 추가해줍니다. 새롭게 추가된 두 가지 손실치는 하이퍼파라미터인 $c_1$과 $c_2$로 조절됩니다. 위의 식에서 이 모든게 적용된 최종적인 PPO 알고리즘의 목적함수를 확인할 수 있습니다.
파이썬 코드
import gym
import time
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
from torch.distributions import Categorical
from torch.utils.tensorboard import SummaryWriter
writer = SummaryWriter("logs/ppo")
#Hyperparameters
learning_rate = 0.0005
gamma = 0.98
lmbda = 0.95
eps_clip = 0.1
K_epoch = 3
T_horizon = 20
class PPO(nn.Module):
def __init__(self):
super(PPO, self).__init__()
self.data = []
self.fc1 = nn.Linear(4,256)
self.fc_pi = nn.Linear(256,2)
self.fc_v = nn.Linear(256,1)
self.optimizer = optim.Adam(self.parameters(), lr=learning_rate)
def pi(self, x, softmax_dim = 0):
x = F.relu(self.fc1(x))
x = self.fc_pi(x)
prob = F.softmax(x, dim=softmax_dim)
return prob
def v(self, x):
x = F.relu(self.fc1(x))
v = self.fc_v(x)
return v
def put_data(self, transition):
self.data.append(transition)
def make_batch(self):
s_lst, a_lst, r_lst, s_prime_lst, prob_a_lst, done_lst = [], [], [], [], [], []
for transition in self.data:
s, a, r, s_prime, prob_a, done = transition
s_lst.append(s)
a_lst.append([a])
r_lst.append([r])
s_prime_lst.append(s_prime)
prob_a_lst.append([prob_a])
done_mask = 0 if done else 1
done_lst.append([done_mask])
s,a,r,s_prime,done_mask, prob_a = torch.tensor(s_lst, dtype=torch.float), torch.tensor(a_lst), \
torch.tensor(r_lst), torch.tensor(s_prime_lst, dtype=torch.float), \
torch.tensor(done_lst, dtype=torch.float), torch.tensor(prob_a_lst)
self.data = []
return s, a, r, s_prime, done_mask, prob_a
def train_net(self):
s, a, r, s_prime, done_mask, prob_a = self.make_batch()
for i in range(K_epoch):
td_target = r + gamma * self.v(s_prime) * done_mask
delta = td_target - self.v(s)
delta = delta.detach().numpy()
advantage_lst = []
advantage = 0.0
for delta_t in delta[::-1]:
advantage = gamma * lmbda * advantage + delta_t[0]
advantage_lst.append([advantage])
advantage_lst.reverse()
advantage = torch.tensor(advantage_lst, dtype=torch.float)
pi = self.pi(s, softmax_dim=1)
pi_a = pi.gather(1,a)
ratio = torch.exp(torch.log(pi_a) - torch.log(prob_a)) # a/b == exp(log(a)-log(b))
surr1 = ratio * advantage
surr2 = torch.clamp(ratio, 1-eps_clip, 1+eps_clip) * advantage
loss = -torch.min(surr1, surr2) + F.smooth_l1_loss(self.v(s) , td_target.detach())
self.optimizer.zero_grad()
loss.mean().backward()
self.optimizer.step()
def main():
env = gym.make('CartPole-v1')
model = PPO()
score = 0.0
print_interval = 20
for n_epi in range(1000):
s, _ = env.reset()
done = False
while not done:
for t in range(T_horizon):
prob = model.pi(torch.from_numpy(s).float())
m = Categorical(prob)
a = m.sample().item()
s_prime, r, done, truncated, info = env.step(a)
model.put_data((s, a, r/100.0, s_prime, prob[a].item(), done))
s = s_prime
score += r
if done:
break
model.train_net()
if n_epi%print_interval==0 and n_epi!=0:
writer.add_scalar("score", score/print_interval, n_epi)
print("# of episode :{}, avg score : {:.1f}".format(n_epi, score/print_interval))
score = 0.0
env.close()
writer.close()
# ---------- 학습이 끝난 뒤, 렌더링 테스트 ----------
print("Now testing (rendering) the final policy...")
# render_mode='human' 으로 재생성
env_render = gym.make('CartPole-v1', render_mode='human') # Changed to 'CartPole-v1'
# 테스트 에피소드 횟수 설정
test_episodes = 3
for ep in range(test_episodes):
s, _ = env_render.reset()
done = False
total_reward = 0
while not done:
# Select action without exploration
prob = model.pi(torch.from_numpy(s).float())
a = torch.argmax(prob).item()
s_prime, r, done, truncated, info = env_render.step(a)
env_render.render()
s = s_prime
total_reward += r
time.sleep(0.02) # Add a small delay for better visualization
print(f"Test Episode {ep+1}: Total Reward = {total_reward}")
env_render.close()
if __name__ == '__main__':
main()
PPO를 CartPole-V1환경에 사용한 파이썬 예시 코드입니다. 학습 부분을 좀 더 자세하게 살펴보겠습니다.
def train_net(self):
s, a, r, s_prime, done_mask, prob_a = self.make_batch()
for i in range(K_epoch):
td_target = r + gamma * self.v(s_prime) * done_mask
delta = td_target - self.v(s)
delta = delta.detach().numpy()
advantage_lst = []
advantage = 0.0
for delta_t in delta[::-1]:
advantage = gamma * lmbda * advantage + delta_t[0]
advantage_lst.append([advantage])
advantage_lst.reverse()
advantage = torch.tensor(advantage_lst, dtype=torch.float)
pi = self.pi(s, softmax_dim=1)
pi_a = pi.gather(1,a)
ratio = torch.exp(torch.log(pi_a) - torch.log(prob_a)) # a/b == exp(log(a)-log(b))
surr1 = ratio * advantage
surr2 = torch.clamp(ratio, 1-eps_clip, 1+eps_clip) * advantage
loss = -torch.min(surr1, surr2) + F.smooth_l1_loss(self.v(s) , td_target.detach())
self.optimizer.zero_grad()
loss.mean().backward()
self.optimizer.step()
위의 train_net에서 PPO의 핵심 아이디어인 Clipping을 확인할 수 있습니다. surr2를 구할 때 torch.clamp(ratio, 1-eps_clip, 1+eps_clip) * advantage 라는 코드로 구하는데요, 그 바로 다음 줄에서 surr1(TRPO의 목적함수)와 surr2 중 작은 값을 손실로 취하는 것을 확인할 수 있습니다.
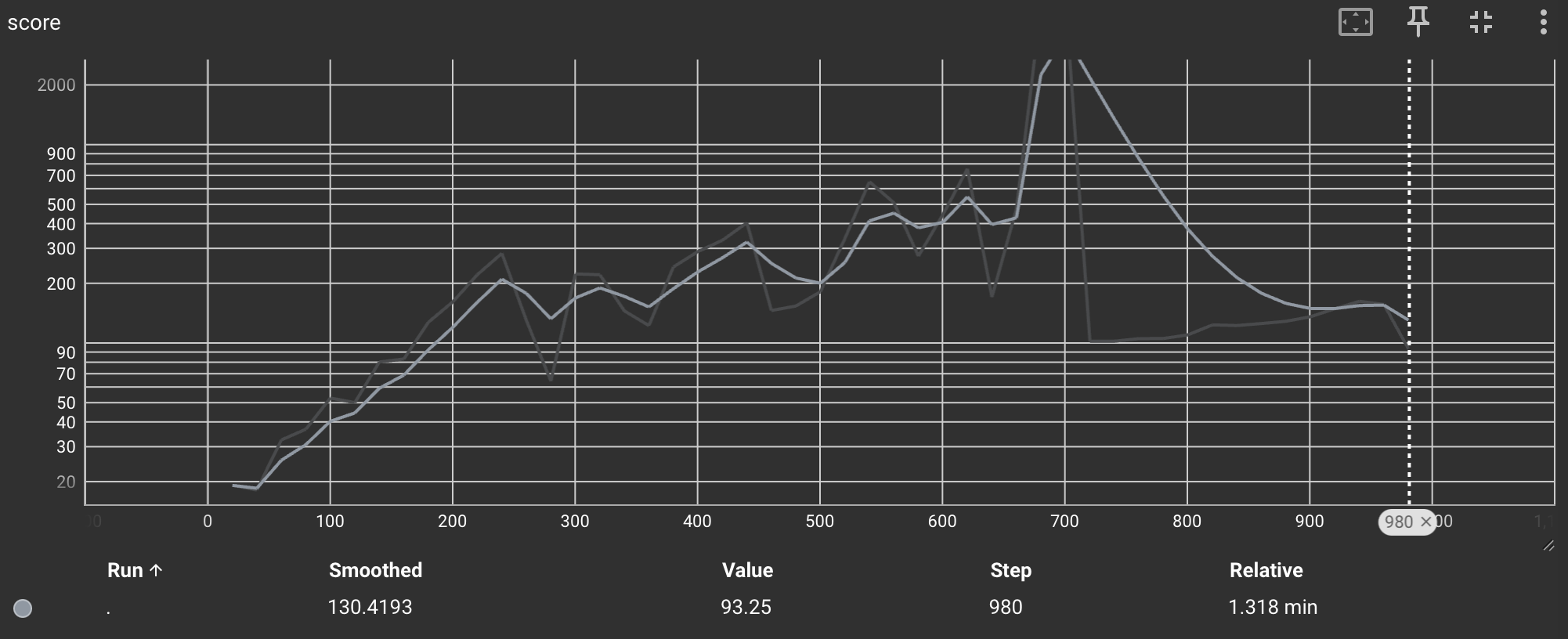
위 그림은 학습 결과입니다. 700 Iteration에서 최고점을 찍고 성능이 많이 하락했는데, 총 Iteration의 수가 늘어나면 해결될 문제로 보입니다. 아래는 테스트 렌더링 결과입니다.
댓글남기기