강화학습 03: 유한 마르코프 결정 과정
글에 들어가기 앞서…
이 포스팅은 ‘강화학습‘에 대한 내용을 담고 있습니다.
자료 출처: 단단한 강화학습, Reinforcement Learning An Introduction , 2nd edition. 리처드 서튼, 앤드류 바트로, 김성우(옮긴이)
유한 마르코프 결정 과정
본격적인 강화학습 문제를 해결하기 위해서는, 새로운 가정이 필요합니다. 그것은 우리가 해결하려는 강화학습 문제가 마르코프 결정 과정(Marcov Decision Process)을 따른다는 가정입니다. 이 포스팅에서는 마르코프 결정 과정중에서도, 유한 마르코프 결정 과정을 다룹니다. 유한 마르코프 결정 과정에 대해 이해하기 위해서는 마르코프 결정 과정을 먼저 알 필요가 있습니다. 그리고 나면, 그 개념에서 무엇을 유한으로 설정하는지 확인할 수 있습니다.
마르코프 결정 과정
마르코프 결정 과정이란 순차적 행동 결정 문제를 수학적으로 표현한 것인데요, 마르코프 결정 과정에는 마르코프 특성이라는 아주 중요한 특징이 존재합니다. 마르코프 특성이란 오직 현재의 상태만으로 미래 상태의 분포가 결정되는 것을 의미합니다. 이게 당연하지 않은 이유는, 현재 뿐만 아니라 과거의 상태들이 미래 상태의 분포에 영향을 미치는 것이 당연하기 때문인데요, 마르코프 결정 과정에서는 과거 상태의 영향력을 생각하지 않습니다. 그렇게 할 수 있는 이유는 현재 상태만으로 미래 상태의 분포를 충분히 설명할 수 있는 문제를 다루기 때문입니다.
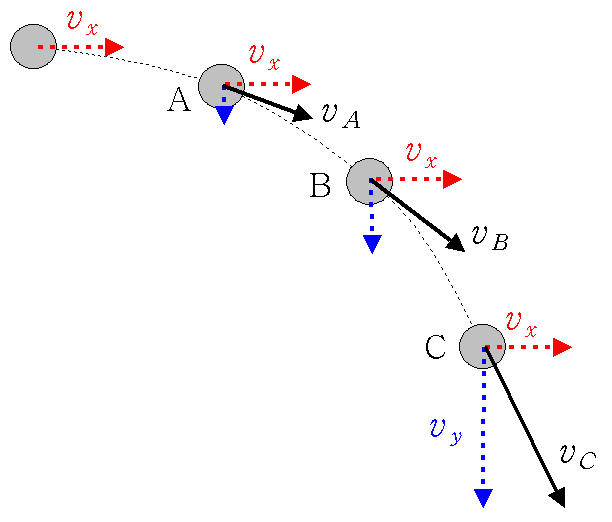
위는 지구 위에서 공의 움직임을 나타내는 그림입니다. 만약 특정 시점의 공의 $x$축 방향 속도와 $y$축 방향의 속도를 안다면, 그 다음 시점의 상태를 알아낼 수 있습니다. 그리고 다음 시점의 상태를 알아낼 때, 현재 상태 이전의 정보는 전혀 필요하지 않은데요, 이는 현재 상태 정보만으로 미래 상태를 추정하기 충분하기 때문입니다.
마르코프 결정 과정은 강화학습 문제를 이론적으로 정교하게 설명할 수 있게 하는 이상적인 수학적 형태입니다. 당연하게도 모든 강화학습 문제가 마르코프 특성을 만족하지는 못합니다. 그런 경우에는 강화학습 문제가 마르코프 특성을 만족하도록 변형시키는데요, 당연하게도 원래 문제에서 멀어진다는 단점이 있기 때문에, 적절한 조절이 필요합니다.
에이전트-환경 인터페이스
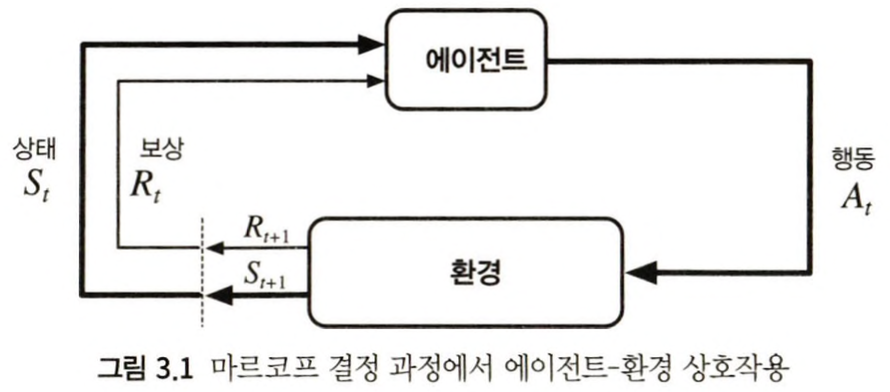
마르코프 결정 과정은 마르코프 특성을 만족하는 문제를 해결하기 위해 고안된 틀입니다. 마르코프 결정 과정에서는 학습자가 통제할 수 있는 것과 없는 것을 나누어 생각합니다. 마르코프 결정 과정에서 학습자는 에이전트(Agent)라고 불리는데요, 에이전트는 환경으로부터 받은 신호를 기반해 상태($S \in \mathcal{S}$)(State) 정보를 생성합니다. 그리고 그것을 기반으로 행동($A_t \in \mathcal{A(s)}$)(Action)을 선택합니다. 그리고 행동의 결과로 보상($R_t \in \mathcal{R} \in \mathbb{R}$)(Reward)을 받습니다. 이 일련의 과정이 계속 반복되는데요, 그 나열들을 궤적(Trajectory)라고 합니다.
학습자가 통제할 수 없는 것은 환경(Environment)입니다. 강화학습 문제에서 에이전트를 제외한 모든 것이 환경인데요, 에이전트와 환경의 경계는 우리가 직관적으로 받아들이는 수준보다 좀 더 에이전트에 가깝게 위치합니다. 예를 들어, 로봇 제어 상황을 생각해 본다면, 로봇을 이루는 부품들은 에이전트 행동으로 결정할 수 없는 환경 요소입니다. 에이전트와 환경의 경계는 목적에 따라 다른 위치에 놓일 수 있는데요, 어떤 경우든 해당 경계는 에이전트의 절대적 제어의 한계라고 생각할 수 있습니다.
이제 유한이라는 단어가 어디에 적용되는지를 알 수 있는데요, 유한 마르코프 결정 과정에서의 유한은, 상태, 행동, 보상의 집합이 유한한 원소를 가지고 있음을 의미합니다. 이렇게 정의하고 나면, 보상과 상태집합에 대해 이산 확률 분포를 정의할 수 있습니다(원소가 유한하기 때문).
\[p(s', r|s, a) \doteq Pr\{ S_t = s', R_t = r|S_{t-1} = s, A_{t-1} = a \}\]위의 함수 $p$는 MDP의 동역학(Dynamics)을 정의합니다. 동역학 함수는 결정론적 함수인데요, 여기에서 결정론적이라는 표현에 혼동할 수 있는데요, 이는 상태의 전이 자체는 확률적으로 일어나는데, 그 확률 자체가 $[0, 1]$의 특정 실수값으로 고정되어 있다는 의미입니다. 함수 $p$를 가지고 있다면, 이를 사용해 환경에 관한 모든 정보를 계산할 수 있습니다. 하지만, 함수 $p$가 주어지는 것과 강화학습 문제 해결은 별개의 문제입니다. 예를 들어, 우리가 특정 보드게임의 규칙에 대해서 배우는 것이 곧 함수 $p$가 주어지는 것인데요, 규칙을 정확히 안다고 해서 곧바로 잘 할 수 있는 것은 아니죠.
전이 그래프
강화학습 문제를 요약해서 보여주는 유용한 방법이 있는데요, 바로 전이 그래프(Transition Graph)입니다.
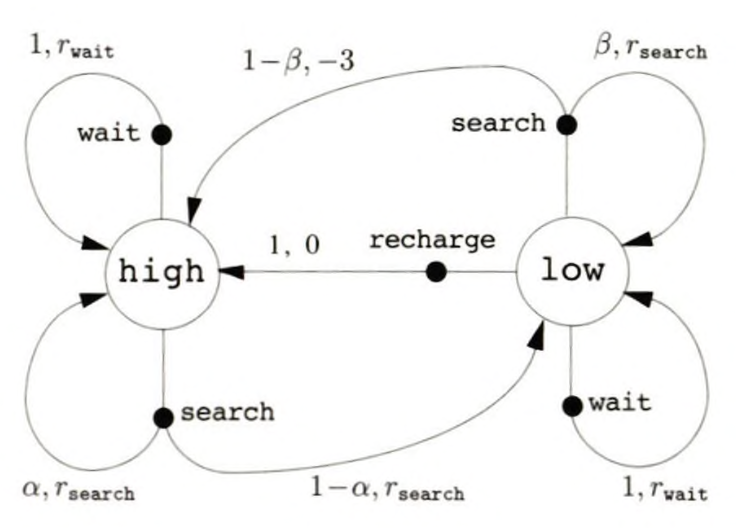
그래프에서 커다란 원은 상태를 의미하고, 이를 상태 노드(State Node). 상태에서 나가는 화살표가 존재하고, 화살표 위에는 항상 동그란 검은 점이 존재합니다. 동그란 검은 점은 행동을 의미하고, 이를 행동 노드(Action Node). 행동 노드에서 분기가 발생하는 경우가 있고, 그렇지 않은 경우도 있는데요, 분기가 발생하는 경우는 행동으로 인해 도달하는 상태가 확률적으로 결정됩니다.
목표와 보상
우리가 다루는 문제는 더 이상 슬롯머신의 레버를 당기는 것과 같이 한 번의 행동으로 결정되지 않습니다. 우리는 일련의 행동을 통해서 문제를 해결해가는 과정 중에 보상 신호를 계속 수집합니다. 이런 경우에 에이전트는 순간의 즉각적인 보상 신호를 탐닉하는 것이 아니라 장기적으로 누적된 보상 신호의 합을 최대화해야합니다. 이를 보상 가설(Reward Hypothesis)라고 합니다. 즉, 에이전트의 목표는 누적된 보상의 최대화입니다.
보상과 에피소드
에이전트의 목표는 누적 보상의 최대화인데요, 특정 시점 $t$ 이후에 받는 연속된 보상을 입력으로 하는 함수의 결과 값을 기대되는 이득(Expected Return)이라고 하고, $G_t$로 표현합니다. 가장 간단한 경우는 단순한 보상의 총합인데요, 필요에 따라 기대되는 이득은 다양하게 정의될 수 있습니다.
\[G_t \doteq R_{t+1} + R_{t+2} + R_{t+3} + \cdot\cdot\cdot + R_{T}\]위 식에서 $T$는 최종 시간 단계를 의미하는데요, 에이전트의 작업이 유한 시간 안에 끝나는 작업인 경우에 이렇게 최종 시간 단계가 존재합니다. 일련의 행동과 상태, 그리고 보상을 받아나가는 하나의 작업을 에피소드(Episode)라고 부르는데요, 위와 같이 유한 시간 안에 끝나는 작업을 에피소딕 작업(Episodic Task)이라고 합니다.
하지만 모든 작업이 유한 시간 안에 결정되는 것은 아닙니다. 예를 들어 연속적인 프로세스 제어 작업이나, 수명이 긴 로봇인 경우 최종 시간 단계가 존재하지 않고 한계 없이 계속 작업이 이어집니다. 이를 연속적인 작업(Continuing Task)이라고 부릅니다. 이런 종류의 작업을 에피소딕하게 접근하면 다소 어려움이 있는데요, 보상이 무한하게 나열되기 때문에 기대되는 이득 역시 항상 무한이 됩니다. 우리는 기대되는 이득을 사용해 각 상태의 좋고 나쁨을 평가하는데요, 모든 상태의 기대되는 이득이 무한이 되면, 좋은 행동을 선택하기 어렵습니다. 따라서 할인(Discounting)이라는 새로운 개념을 추가합니다.
\[G_t \doteq R_{t+1} + \gamma R_{t+2} + \gamma^2 R_{t+3} + \cdot \cdot \cdot = \sum_{k=0}^\infty \gamma^kR_{t+k+1}\] \[= R_{t+1} + \gamma G_{t_1}\]위 식에서 $\gamma$는 할인율(Discounting Rate)라고 불리는데, $[0, 1]$의 값을 가집니다. 그리고 위 식 전체를 할인된 이득(Discounting Return)이라고 부릅니다. 할인된 이득은 현재 시점으로부터 먼 시점의 기대 보상을 낮게 점차적으로 낮게 평가하는데, 이 정도는 할인율을 통해 정해집니다. 할인율이 극단적으로 0으로 설정되는 경우 할인된 이득은 당장 다음 보상만을 나타내게 되고, 에이전트 역시 당장의 보상만을 최대화하는 근시안적인(Myoptic) 행동을 하게 됩니다.
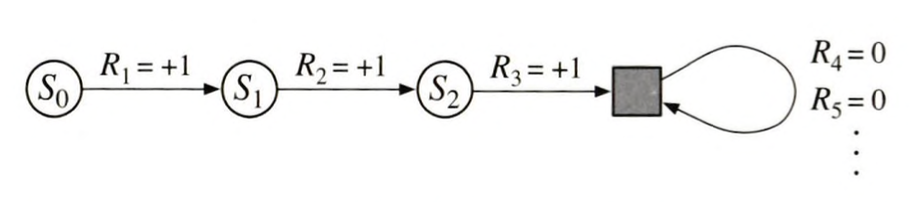
근데 생각을 달리하면 에피소딕 작업도 할인된 이득으로 표현이 가능합니다. 실제로는 $T$시점에서 에피소드가 끝났지만, 그 이후로도 값이 0인 보상이 계속 존재한다고 가정하고 $\gamma$값을 1로 설정하면, 에피소딕 작업에서 단순히 보상의 합을 기대되는 이득으로 사용한 것과 정확히 일치됩니다. 때문에 기대되는 이득은 대부분의 경우에 할인된 이득의 형식을 따르게 됩니다.
정책 & 가치함수
정책과 가치함수는 긴밀하게 관계되어 있습니다. 사실 가치함수를 정의한 이유가 이를 기반으로 정책이 결정하기 위함이었습니다. 반대로 가치함수의 값 역시 정책의 영향을 받습니다. 가치함수는 해당 행동 이후로 받게될 보상의 평균값이므로 정책이 바뀌면 가치함수의 값 역시 변화하게 됩니다.
\[\pi(a|s)\]위 식은 정책의 표현을 나타내는데요, 이렇게 표현될 수 있는 이유는 우리의 에이전트가 마르코프 결정 과정을 따르기 때문입니다. 마르코프 결정 과정에서는 현재 상태($s$)만으로 행동을 결정하기 때문에 조건부에 자질구레한 확률변수 여럿이 들어가지 않고 오직 현재 상태만이 들어갑니다. 그리고 위 식의 값은 $[0, 1]$의 값을 가집니다.
\[v_{\pi}(s) \doteq \mathbb{E}_{\pi}[G_t|S_t = s] = \mathbb{E}_{\pi}[\sum_{k=0}^{\infty}\gamma^kR_{t+k+1}|S_t = s]\] \[q_{\pi}(s, a) \doteq \mathbb{E}_{\pi}[G_t|S_t = s, A_t = a] = \mathbb{E}_{\pi}[\sum_{k=0}^{\infty}\gamma^kR_{t+k+1}|S_t = s, A_t = a]\]위 두 식은 정책 $\pi$에 대한 상태 가치 함수(State-value Function for Policy $\pi$)와 정책 $\pi$에 대한 행동 가치 함수(Action-value Function for Policy $\pi$)를 나타냅니다. 행동 가치 함수의 경우 입력 값이 행동 뿐만이 아니라 상태가 함께 들어가는데요, 이는 행동이 가지는 가치가 상태에 대해 독립적이지 않기 때문입니다. 예를 들어 복싱이라는 하나의 에피소딕한 작업에서 상대가 가드를 올리지 않은 상태와 올린 상태에서 훅이라는 행동이 가지는 가치는 다를 텐데요, 이처럼 동일한 행동이라 할지라도 상태에 따라 행동의 가치는 달라지게 됩니다. 때문에 행동 가치 함수의 입력으로 행동과 상태, 두 개의 입력이 들어가게 됩니다.
특이한 점이 있는데요, 가치 함수에는 가치 함수에는 정책이 아랫첨자로 들어가는데, 정책을 나타내는 식에는 가치 함수가 아랫첨자로 들어가지 않습니다. 둘 모두는 서로 영향을 주고 받는 사이인데, 왜 가치 함수에만 정책이 아랫첨자로 들어갈까요? 이유는 정책이 단일 에피소드 내에서는 정책이 가치 함수의 영향을 받지 않는다는 점에 있습니다. 이를 이해하기 위해서는 강화학습 에이전트가 업데이트되는 방식에 대해 알 필요가 있습니다.
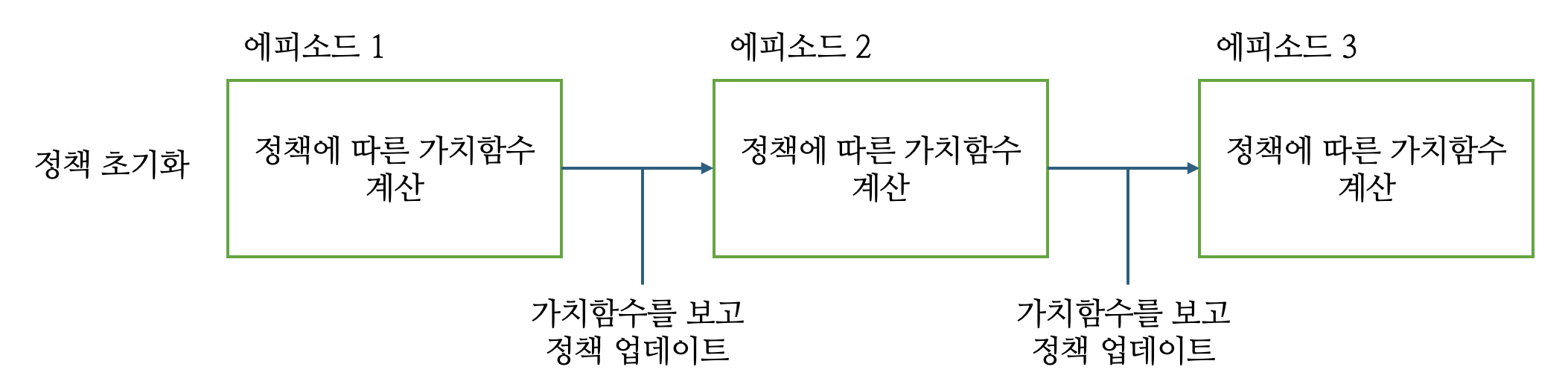
일련의 에피소드가 끝난 후에는 가치함수의 값을 참고해 정책이 업데이트 될 수는 있지만, 정책은 하나의 에피소드에서 고정된 상태로 존재합니다. 따라서 정책을 표현하는 식에는 가치함수가 드러나지 않습니다. 반면 가치함수의 값은 일련의 에피소드에서 직접 경험해 수집한 보상을 기반으로 추정되는데요, 이때 수집한 에피소드는 에이전트의 정책에 의존해 생성된 것이기 때문에 정책이 직접적으로 관여합니다. 그리고 가치 함수는 재귀적인 관계식을 통해 표현될 수 있는데, 이 식에는 정책이 당연히 포함됩니다.
\[v_{\pi}(s) \doteq \mathbb{E}_{\pi}[G_t|S_t = s]\] \[= \mathbb{E}_{\pi}[R_{t+1} + \gamma G_{t+1}|S_t = s]\] \[= \sum_a\pi(a|s)\sum_{s'}\sum_rp(s', r|s, a)[r + \gamma v_\pi(s')]\]위 식을 벨만 방정식(Bellman Equation)이라고 부릅니다. 수많은 에피소드를 통해 얻어진 보상의 평균을 통해 가치함수를 추정할 수도 있지만, 위와 같이 $p$(환경)가 주어진 상황에서는 벨만 방정식의 풀이를 통해 현 정책을 따르는 가치 함수를 계산할 수 있습니다.
최적 정책과 최적 가치 함수
벨만 방정식 아이디어를 사용하면, 환경이 주어졌을 때, 최적 정책(Optimal Policy)을 구할 수 있습니다. 최적 정책이란 다른 모든 정책보다 좋은 정책을 의미하는데요, 이 설명의 의미를 이해하기 위해서는 정책의 좋음의 의미에 대해 알 필요가 있습니다.
정책 $\pi$의 모든 상태에 대한 이득의 기댓값이 정책 $\pi’$의 모든 동일한 상태에 대한 기댓값보다 크거나 같을때, 정책 $\pi$가 정책 $\pi’$보다 좋다라고 표현합니다. 다른 어떤 정책보다도 좋은 정책을 최적 정책이라고 하고, 최적 정책만이 가지는 상태 가치 함수를 최적 상태 가치 함수라고 부릅니다. 그리고 당연히 최적 행동 가치 함수도 있습니다.
\[v_*(s) \doteq \underset{\pi}{max}\space v_\pi(s)\] \[q_*(s, a) \doteq \underset{\pi}{max}\space q_\pi(s, a)\] \[q_*(s, a) = \mathbb{E}[R_{t+1} + \gamma v_*(S_{t+1})| S_t = s, A_t = a]\]위 수식은 정의에 따라 얻어집니다. 최적 정책의 정의상 모든 상태에서 높은 가치를 가진다는 사실을 표현한 것입니다. 그리고 위 식을 역시 마찬가지로 벨만 방정식의 형태로 표현할 수 있는데, 이를 최적 벨만 방정식(Bellman Optimality Equation)이라고 합니다.
\[v_*(s) = \underset{a}{max}\sum_{s', r}p(s', r|s, a)[r + \gamma v_*(s')]\] \[q_*(s, a) = \sum_{s', r}p(s', r|s, a)[r + \gamma \underset{a'}{max}\space q_*(s', a')]\]위 식을 해석적으로 풀면 최적 가치 함수를 찾을 수 있고, 최적 정책도 얻어지지만, 이를 통해 얻어지는 해는 거의 모든 경우에 쓸모가 없습니다. 사실 이 식을 푸는 것은 모든 경우를 탐색하는 것과 동일합니다. 최적 벨만 방정식을 풀어서 해를 구하는 경우, 아래의 조건을 만족하는 경우에 효과적입니다.
- 환경의 동역학($p$)을 정확히 알고 있다.
- 해의 계산을 완료하기 위한 충분한 계산 능력을 확보하고 있다.
- 마르코프 성질을 가정한다.
1번과 3번 조건을 만족하는 경우는 많은데요, 2번 조건을 만족하는 경우는 거의 존재하지 않습니다. 백게먼 같은 단순한 보드게임 조차 최적 벨만 방정식을 해석적으로 풀기란 현재로썬 불가능합니다. 하물며 훨씬 더 방대한 행동, 상태 공간을 가지는 실전적인 강화학습 문제는 더더욱 어렵습니다. 따라서 강화학습에서는 거의 대부분의 경우에 근사적인 해를 찾는 것으로 만족합니다.
댓글남기기