SGGNet$^2$: Speech-Scene Graph Grounding Network for Speech-guided Navigation
이 포스팅은 ‘SGGNet$^2$: Speech-Scene Graph Grounding Network for Speech-guided Navigation‘에 대한 내용을 담고 있습니다.
논문 주소: https://arxiv.org/pdf/2402.01183
SGGNet$^2$: Speech-Scene Graph Grounding Network for Speech-Guided Navigation
로봇이 음성을 명령어로 바로 받아들일 수 있게 하기 위해 다양한 연구들이 있어 왔습니다. 그간의 연구들에서는 음성을 텍스트로 바꾼 다음, 바뀐 텍스트를 해석해 명령을 수행하는 방법론을 사용했습니다. 그런데 이 방법론에서는 전체 정확도가 음성을 텍스트로 바꾸는 자동 음성 인식(Automatic Speech Recognition) 결과에 크게 의존합니다. 만약에 ASR에서 잘못된 변환을 하게 된다면 로봇이 실제 명령과 다른 동작을 수행하게 됩니다. 이런 문제점을 해결하기 위해서, 이 논문에서는 음성을 ASR에서 텍스트로 바꿔서 사용하는 것 이외에 따로 모델 입력으로 넣어줌으로써 텍스트 변환에서 오류가 발생했을 때, 이를 바로잡을 수 있도록 해줍니다.
Problem Formulation
\[o_t^* = \text{argmax}_{o_t \in \mathcal{O}} P(o_t \mid \Lambda, \mathcal O)\] \[= \text{argmax}_{o_t \in \mathcal{O}} P(o_t \mid Z, \Lambda, \Upsilon, \mathcal O) \, P(Z \mid \Lambda, \Upsilon, \mathcal O) \, P(\Upsilon \mid \Lambda, \mathcal O)\] \[= \text{argmax}_{o_t \in \mathcal{O}} \underbrace{P(o_t \mid Z, \Upsilon)}_{\text {NLG}} \underbrace{P(Z \mid \Lambda) }_{\text{ASR}} \underbrace{P(\Upsilon \mid \mathcal O)}_{\text{World-Model Generator}}\] \[\Lambda: \text{human's speech command}\] \[\Upsilon: \text{world model}\] \[o_i \in \mathcal O: \text{set of detectable objects}\] \[\varrho: \text{detector}\]기존의 language-grounding framework는 위와 같습니다. 로봇의 목적이 물체들과 음성 명령이 주어져 있을 때, 가장 확률이 높은 물체를 고르는 일이라고 한다면, 로봇은 먼저 음성 명령을 텍스트로 변환하고, 바뀐 텍스트를 기반으로 가장 확률이 높은 물체를 고르게 됩니다. 때문에 텍스트 변환이 작업에서의 오류가 곧바로 물체 선택 과정에 전달됩니다.
\[o^*_t = \text{argmax}_{o_t \in \mathcal O} \underbrace{P(o_t \mid \Lambda, \Upsilon_{\text{sg}})}_{\text {SGGNet}^2} \underbrace{P(\Upsilon_\text{sg} \mid \mathcal O)}_{\text{Scene-graph generator}}\]따라서 이러한 문제점을 해결하기 위해서 SGGNet$^2$에서 바로 음성 신호와 scene graph를 바로 받아 목표 물체를 예측합니다. 모델 내부적으로 텍스트 변환을 하는 부분이 있는데, 텍스트로 바꾼 결과만 사용하지 않고 음성 신호를 함께 모델 예측에 사용해, 텍스트로 잘못 변환되더라도 올바르게 목표 물체를 예측할 수 있도록 해줍니다.
Speech-Scene Graph Grounding Network
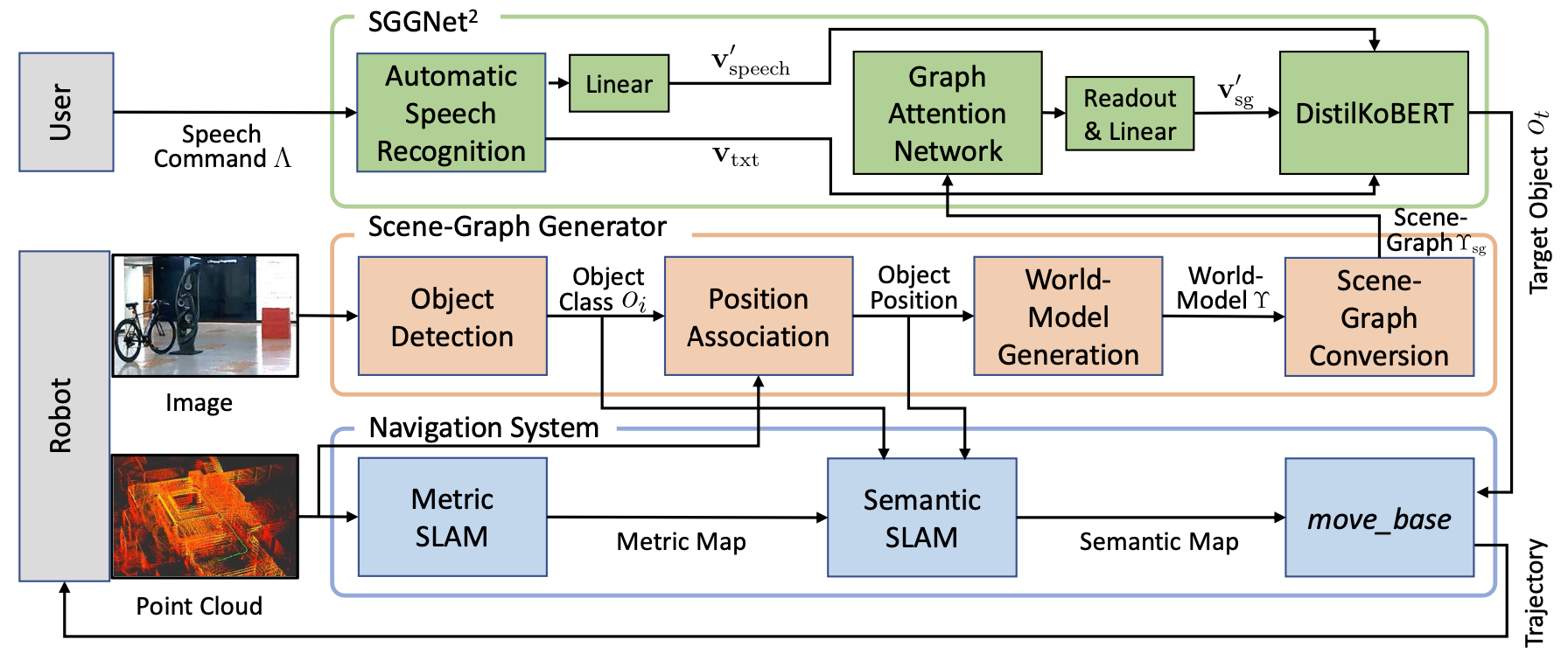
SSGNet$^2$의 전체 구조는 위와 같습니다. ASR에서는 음성 명령을 받아 음성 임베딩과 텍스트 임베딩을 반환합니다. ASR은 인코더-디코더 구조로 되어 있는데, 인코더만을 통과해 얻게되는 벡터가 음성 임베딩 벡터가 되고, 디코더까지 통과해 얻게되는 각 단어 토큰들의 특징 벡터가 텍스트 임베딩 벡터가 됩니다. ASR로는 NVIDIA NeMO ASR을 사용합니다. Scene-graph generator에서는 RGB-D 카메라로부터 데이터를 전달받아 scene-graph를 생성합니다. 이 두 구조로부터 얻은 결과물을 DistilKoBERT의 입력으로 넣어전 후, 최종적으로 목표 물체를 선택하게 됩니다.
Automatic Korean Speech Recognition
NeMo’s Conformer-CTC-based ASR 모델을 사용해 음성 명령을 텍스트 명령으로 변환합니다. 모델이 한국어를 잘 변환할 수 있도록, KsponSpeech 데이터셋으로 사전학습을 수행합니다.
Scene-graph generator
먼저 YOLO를 통해 환경에 존재하는 물체들을 탐지하고 픽셀 좌표계상에서 바운딩 박스를 찾아냅니다. 그 다음, adaptive clustering algorithm을 통해 LiDAR 포인트 클라우드와 2D 물체 좌표를 연관지어 각 물체들의 3D 좌표를 얻어냅니다. 그렇게 얻은 물체의 클래스, 속성, 위치 정보를 world model에 저장합니다. 그리고 나서 물체 사이의 엣지 연결을 만들어주는데, 각 물체들의 3차원 위치 정보를 알고 있으니까, 그 정보들을 바탕으로 ‘left’, ‘right’, ‘front’, ‘behind’ 중에 해당되는 술어로 엣지를 정의해 저장합니다. 위의 술어들 중 두 개 이상이 동시에 만족되는 경우가 있을 수 있는데, 그 경우에는 술어 사이에 공백을 두어 저장합니다(‘left behind’).
End-to-End Grounding Network Design & Training
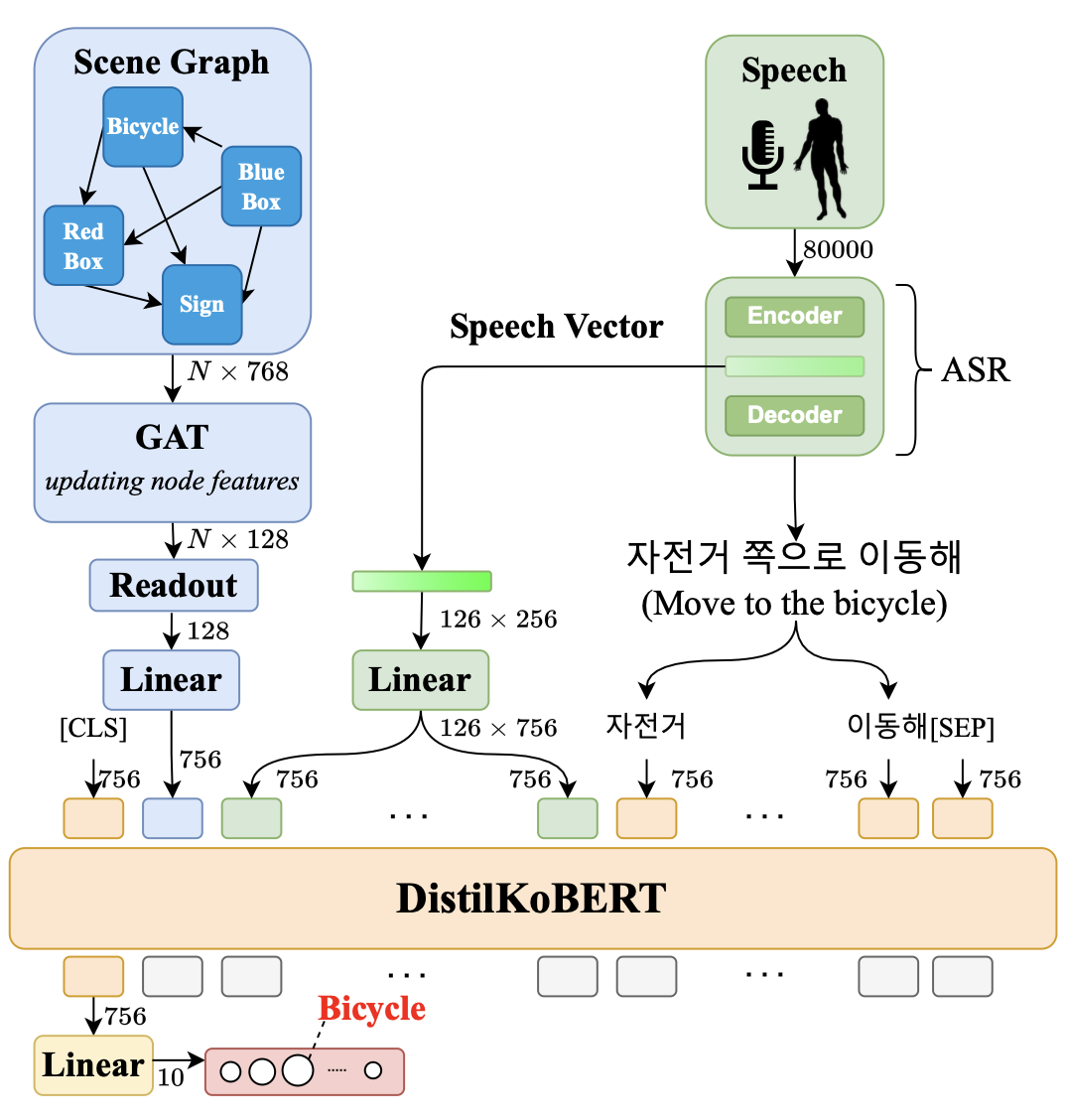
먼저, 이전에 형성된 Scene graph는 노드의 특징과 관계가 자연어(‘bicycle’, ‘left‘)로 표현되어 있는 상태인데, Scene graph의 노드와 엣지를 모델이 받아들일 수 있는 벡터 형태로 바꿔줘야 합니다. 이걸 바꿔줄 때 DistilKoBERT를 사용해 128차원의 벡터로 변환합니다.
\[\mathrm h = f_{\text{GAT}}(\mathrm X, \mathrm E)\] \[\mathrm v_\text{sg} = \phi(\mathrm h)\]이후 그래프를 GAT에 넣어줍니다. GAT를 통해 주변 노드와의 관계를 고려해 노드 벡터가 업데이트 됩니다. 이렇게 얻은 모든 노드들의 특징 벡터를 한데 모아 max-pooling과 readout function을 통해 하나의 128차원 벡터로 만들어줍니다.
\[\mathrm v_\text{speech, t} \quad \mathrm v_\text{txt}\]ASR에서는 음성 명령을 음성 벡터와 텍스트 벡터로 바꿔줍니다. 앞에서 다루었듯 인코더-디코더 구조로 되어있는데, 인코더까지의 결과를 음성 벡터라고 합니다. 음성 벡터는 시간 스텝마다 한 개씩 나오기 때문에 시간 길이만큼의 벡터를 얻게 됩니다. 이 논문에서는 총 길이를 126으로 고정해 사용합니다. 디코더를 통해 생성된 문장이 텍스트 벡터가 됩니다.
정리하면, scene graph에서 얻게되는 특징벡터 하나, 음성 벡터 126개, 마지막으로 텍스트 벡터들을 이전 단계에서 얻었고, 이 모든 벡터들을 토큰으로 삼아 DistilKoBERT의 입력으로 넣어줍니다. 첫 토큰으로 [CLS] 토큰이 추가되어 들어가는데, 다른 BERT 모델과 마찬가지로 마지막 레이어의 [CLS] 토큰에 classifier를 적용시켜 정답 클래스를 선택하게 됩니다.
Experiment Setup
논문의 모델을 평가하기 위해서는 인간 음성 데이터, 음성 데이터를 변환한 텍스트, 그리고 scene graph가 필요합니다. 방향 명령은 동사, 전치사, 물체로 구성됩니다(예시: 자전거로 가). 총 10가지의 목표 클래스가 있고, 각 클래스마다 2개에서 8개의 유사한 표현을 사용합니다. 결과적으로 총 35개의 물체명이 사용되고, 각각을 훈련용과 테스용으로 분류합니다.
각 물체에 대해서 GPT-4를 사용해 390개 정도의 문장을 인위적으로 생성합니다. 이렇게 만들어진 각 명령문에 대응되는 scene graph를 만들어줘야 하는데요, 해당 명령문의 목표 물체를 main node로 설정하고, 2개에서 8개의 추가적인 물체들을 겹치지 않게 잘 배치합니다(중복 클래스는 등장하지 않도록 함). 이제 마지막으로 음성 데이터가 필요한데, 사람이 직접 녹음하지는 않았고, Naver Clova Voice TTS를 통해 문장을 읽게 만들고 음성 파일을 WAV 형식으로 저장합니다.

실험 로봇으로는 12자유도를 가진 사족보행 로봇인 Rainbow Robotics의 RBQ-3을 사용합니다. Ouster OS-1 32-channel LiDAR로 LiDAR 정보를 수집하고, Realsense D435 RGB-D로 RGB와 Depth 정보를 동시에 수집합니다. NVIDIA의 Jetson AGX Orin으로 영상, 음성 데이터를 실시간으로 처리합니다.
로봇의 navigation system은 metric SLAM과 sementic SLAM이라는 두 레이어로 구성됩니다. metric SLAM에서는 FAST-LIO2라는 LiDAR-inertial odomerty framework를 사용해 3차원 클라우드 포인트 맵을 생성합니다. 그리고 만들어진 맵 위에서 경로를 계획합니다. 이어서 sementic SLAM에서는 YOLO를 사용해 각 클러스터에 라벨을 부여해, semantic map을 만들어냅니다. 결과적으로 로봇이 목표 물체의 위치를 알 수 있게 되고, 이걸 바탕으로 속도와 방향을 결정해 로봇을 제어합니다.
Evaluation
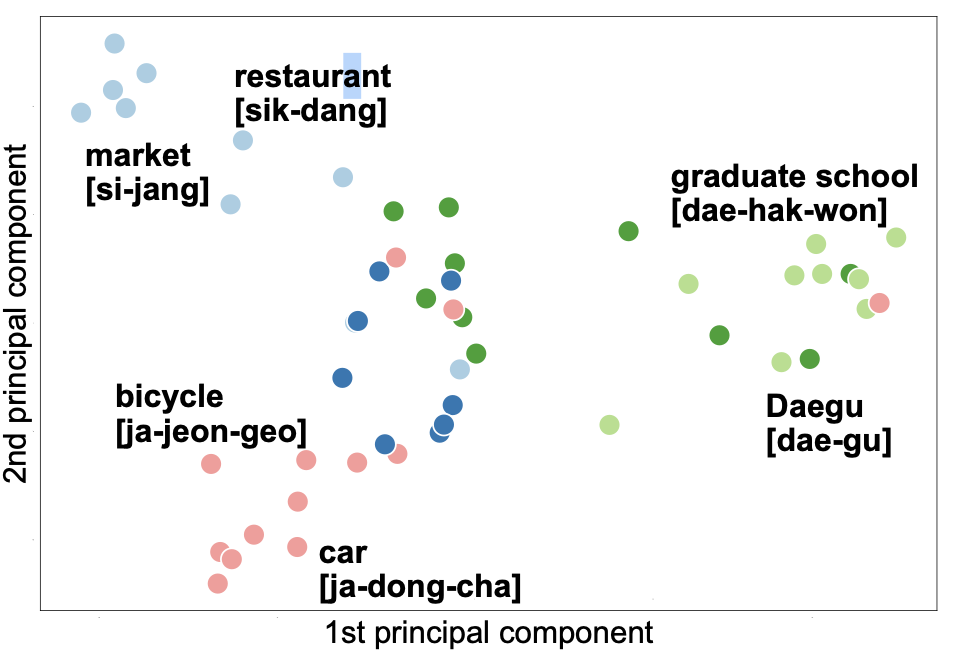
위는 ASR에서 얻은 latent 벡터를 주성분 분석해 그래프로 나타낸 것입니다. 다른 뜻을 가져도 발음이 비슷한 단어들끼리 모여있는 것을 확인할 수 있습니다.
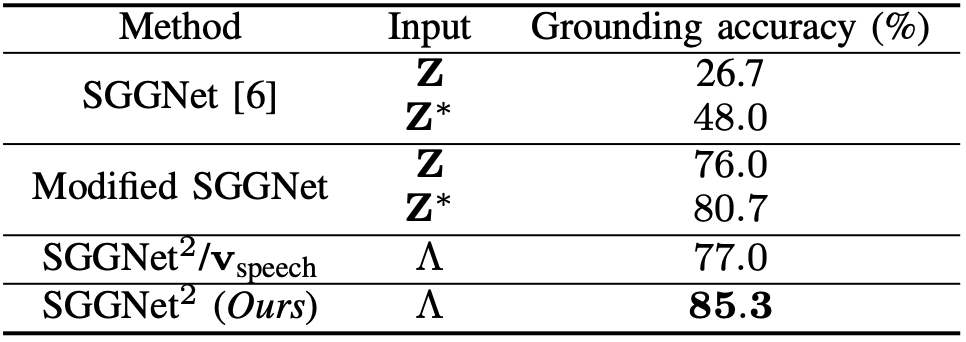
이전 버전의 모델의 성능, 현 모델에서 음성 임베딩을 사용하지 않을 경우의 성능, 그리고 제안한 그대로의 모델의 성능이 어떻게 다른지 확인합니다. 이전 모델과 비교했을 때, 현재 모델의 성능이 더 높게 나타납니다. 이전 모델에 ground truth 텍스트를 넣어준 경우보다도 높은 성능을 보여준다는 점이 특이한 점입니다. 음성 임베딩을 사용하지 않았을 때 성능이 많이 떨어지는 것으로 보아, 음성 임베딩이 텍스트 변환 오류를 잘 보완한다는 것을 확인할 수 있습니다.
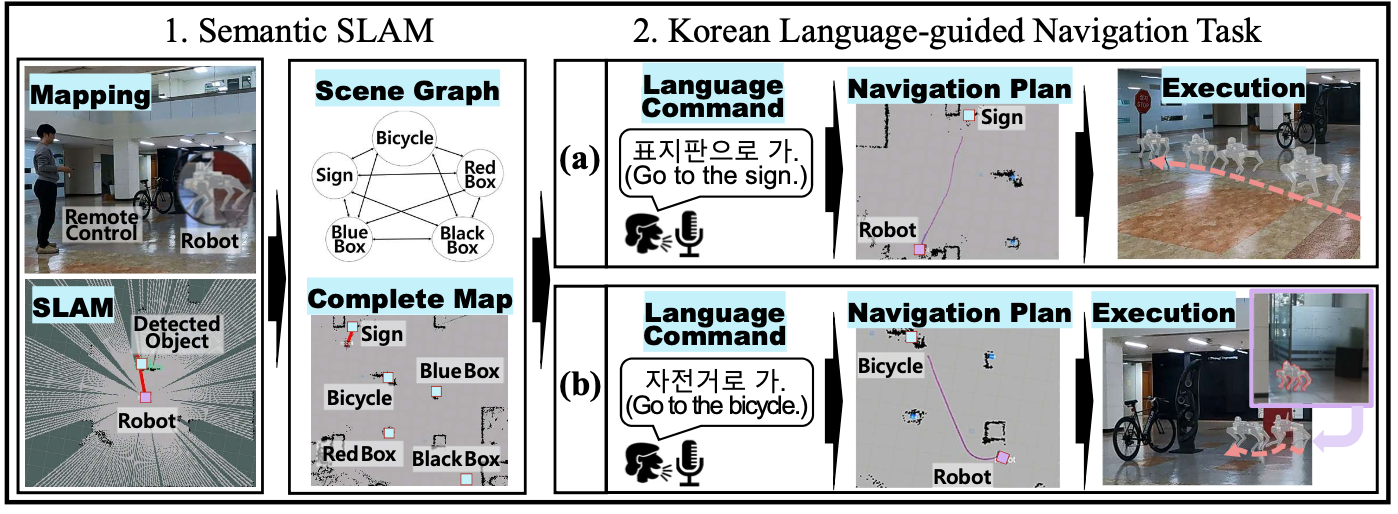
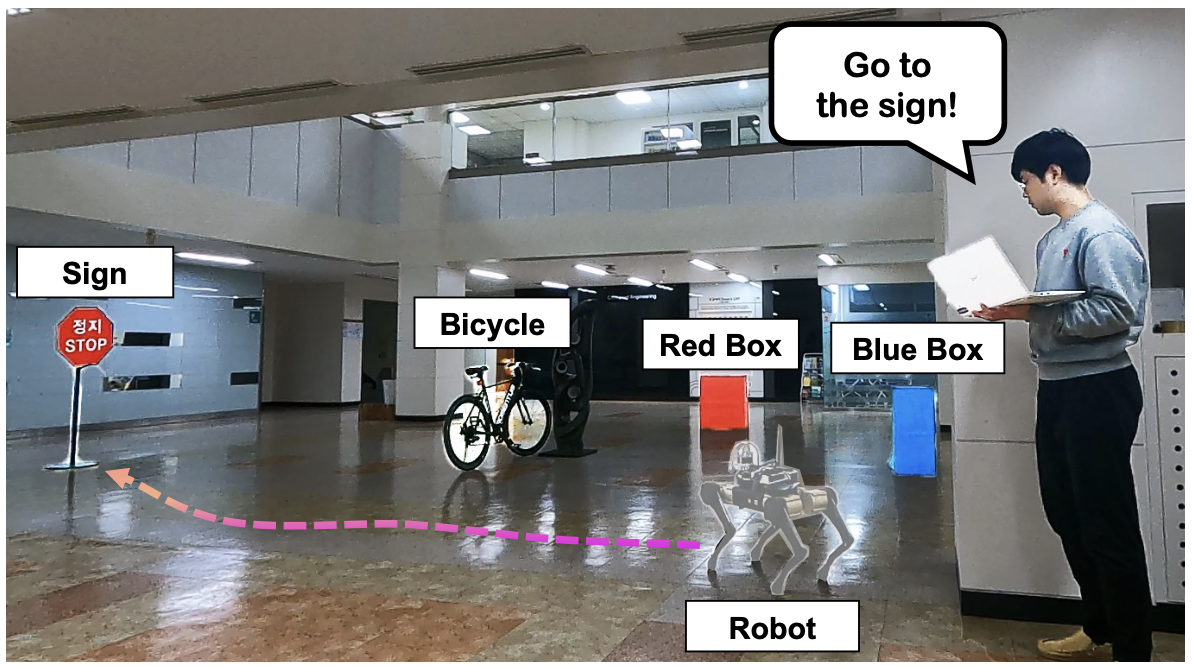
위는 ‘표지판으로 가’ 와 ‘자전거로 가’ 라는 두 음성 명령에 대한 수행 결과입니다. 두 경우에 대해 다 잘 수행한 것을 확인할 수 있었고, 특히 자전거로 이동하는 태스크에서 중간에 기둥에 의해 시야가 가려지는 상황이 발생했는데, scene-graph를 사용해 목표를 잘 찾아갈 수 있었습니다.
Conclusion
논문에서는 scene-graph-based grounding 네트워크를 한국어 음성 인식 네트워크와 결합한 SGGNet$^2$를 제안합니다. 음성 정보를 텍스트 정보로 옮기는데에만 사용하지 않고, 이후 추론 과정에서 추가적으로 사용해 모델의 성능을 높인 점이 인상깊은 부분입니다. 비슷한 발음을 가지는 단어가 음성 임베딩 공간에서 비슷한 위치로 나타난다는 점과, 음성 임베딩을 제거했을 때, 모델의 성능이 떨어진다는 점을 통해 텍스트가 잘못 변환된 경우라고 할지라도 음향 임베딩을 통해 올바른 물체를 선택할 수 있음을 보여줍니다.
댓글남기기