RT-1: Robotics Transformer For Real-World Control at Scale
이 포스팅은 ‘RT-1: Robotics Transformer‘에 대한 내용을 담고 있습니다.
논문 주소 및 자료 출처: https://arxiv.org/pdf/2212.06817, https://arxiv.org/pdf/1709.07871
RT-1: Robotics Transformer
RT-1은 구글에서 발표한 트랜스포머 기반 Everyday Robot 제어 모델입니다. 트랜스포머는 현재 지도학습 분야에서 매우 성공적인 아키텍처로 알려져 있는데요, 이 만능 아키텍처를 로보틱스 분야에서 사용하기 위한 많은 시도들이 있어왔고, 또 많은 시도들이 행해지고 있습니다. RT-1 역시 트랜스포머를 활용한 다양한 로봇 제어 모델들 중 하나입니다. 지시문을 효과적으로 처리하기 위해 도입한 새로운 구조와 대규모 데이터셋을 통한 높은 일반화 성능이 본 논문의 흥미로운 점입니다.
Introduction
모방학습이나 강화학습을 사용한 많은 End-to-End 학습에서 꽤 괜찮은 성능을 보여주는 모델들은 많이 있지만(당시 배경), 일반화 성능에서 빼어난 성능을 보여주는 모델은 없었습니다. 일반화 성능이 좋다는 것 자체만으로 다양하고 새로운 태스크들을 처리할 수 있다는 장점이 있습니다. 더욱이 모델이 일반화 성능이 좋다는 것은 다양한 모델에서 일반적인 패턴을 학습할 수 있다는 것을 의미합니다. 하지만, 자연어로 된 지시어와 함께 로봇의 카메라로 받아들이는 이미지 데이터를 함께 처리해야하는 멀티모달 모델에, 그것도 실시간 제어를 해야한다는 제약조건 하에서(모델의 크기에 제약) 일반화 능력을 갖춘 모델을 만들어 내는 것은 어려운 일입니다. 이 논문에서는 멀티모달 분야에서 최근에 자주 사용되는 FiLM 구조와 함께 트랜스포머 구조를 사용해 제한된 파라미터 개수로 높은 일반화 성능을 달성할 수 있음을 보여줍니다.
Model Structure
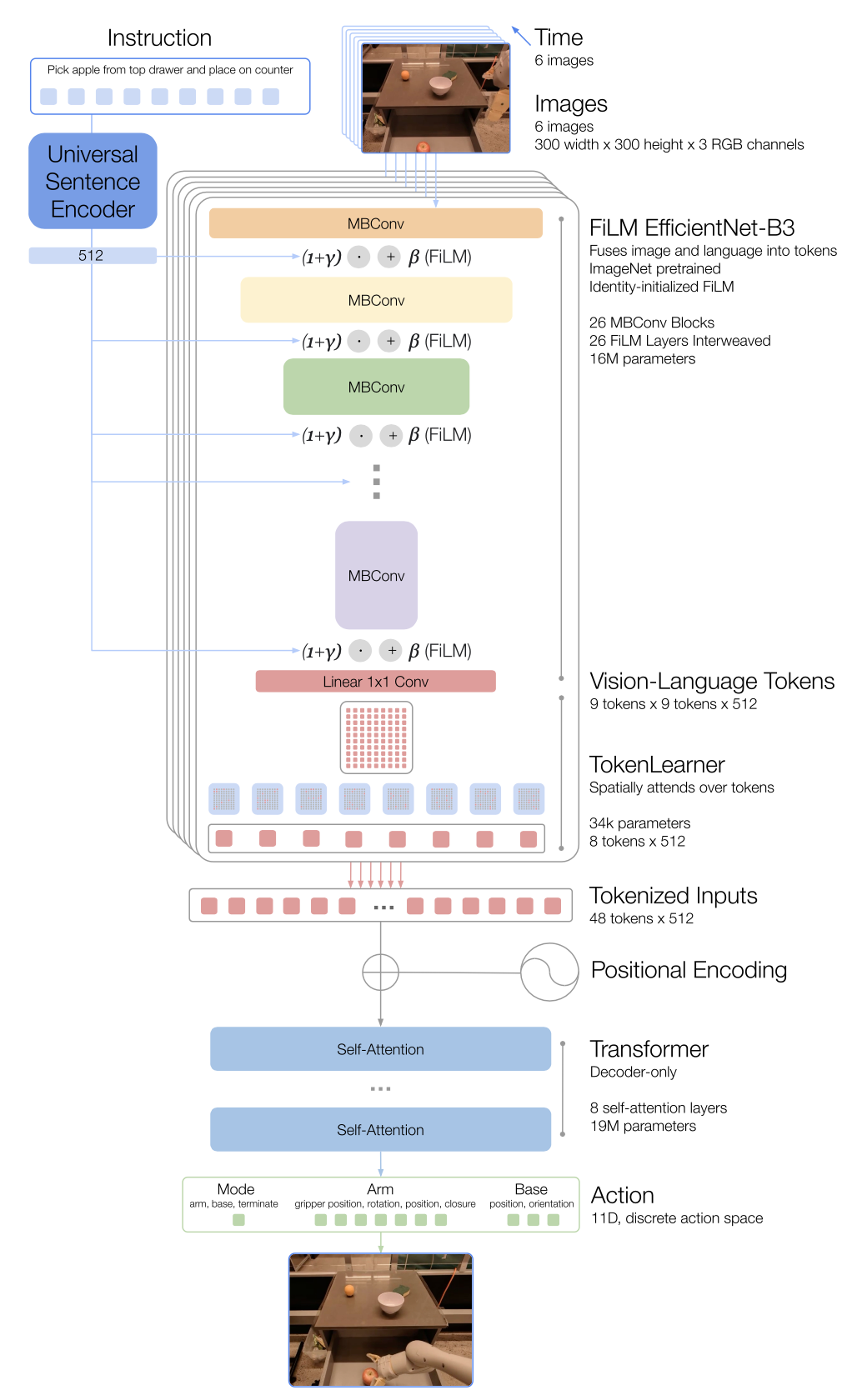
위는 RT-1 모델의 전체 구조 도식입니다. RT-1은 이미지와 지시어를 동시 처리해야하는 멀티모달 모델입니다. 따라서 멀티모달 모델 중에서 자주 사용되는 FiLM 구조를 통해 이미지와 지시어의 정보를 통합시킵니다. 대부분의 모델들은 반복되는 블록을 여러 번 쌓아 사용하는 구조로 되어 있는데요, 그 반복되는 구조들 사이에 FiLM이라는 새로운 구조를 추가해 모델에 지시어 정보를 통합시킬 수 있습니다. FiLM 구조는 블록 사이사이의 activation에 Affine Transformation을 가하게 됩니다. Affine Tranformation에 필요한 두 파라미터(weight, bias)는 GRU와 NN(단층 MLP)을 통해 구해집니다. 이 구조를 통해 모델이 텍스트 정보를 성공적으로 흡수할 수 있다는 사실이 이미 다양한 실험들을 통해 입증되었습니다.
FiLM의 자세한 동작은 아래의 논문 링크에서 확인할 수 있습니다.
RT-1은 학습 효율성을 위해 ImageNet에서 미리 학습된 EfficientNet-B3을 사용합니다. EfficientNet-B3는 2019년에 소개된 모델이기 때문에 당연히 FiLM구조가 포함되어있지 않습니다. RT-1에서는 EfficientNet-B3에 FiLM 구조를 군데군데 삽입하는데, 어떤 모델에 새롭게 구조를 추가하면 성능이 완전히 붕괴하게 돼, 사전 학습된 파라미터의 이득을 취하기 어려워집니다. 따라서 FiLM이 0의 출력을 내도록 가중치를 초기화해, 모델이 FiLM 구조를 자연스럽게 받아들일 수 있도록 합니다. FiLM에 들여보내는 임베딩 벡터는 Universal Sentence Encoder를 통해 생성됩니다. Universal Sentence Encoder는 단일 토큰만 보는게 아니라, 전체 문장의 구조를 고려해서 임베딩을 생성하기 때문에, 각 토큰 임베딩에 문장의 전체적인 의미가 포합됩니다.
EfficientNet-B3의 출력 크기는 9 * 9 * 512의 텐서로 설정합니다. 즉, EfficientNet-B3의 출력이 일종의 이미지인 것인데, 이미지의 픽셀 각각이 비주얼 토큰이 됩니다(임베딩 차원 깊이가 512이 81개의 토큰). 여기에서 81개의 토큰을 곧바로 트랜스포머의 입력으로 사용하지 않고 TokenLearner를 통해 토큰의 개수를 8개로 줄여줍니다. TokenLearner는 Attention을 통해 각 8개의 토큰들이 81개의 토큰들 중 중요한 정보만을 담도록 학습됩니다. 즉, 81개의 토큰들 중에 가장 중요한 부분만을 Soft-Selection하기 위해 8개의 Attention Map을 학습합니다.
TokenLearner까지의 단계를 끝마치면 하나의 이미지와 지시문의 결과가 8개의 토큰으로 바뀌게 되는데, 모델에게 연속적인 시각 정보를 제공하기 위해 연속되는 6개의 이미지를 사용합니다. 따라서 총 48개의 토큰이 트랜스포머의 입력으로 사용됩니다. 48개의 토큰은 Positional Encoding이 추가된 상태로 트랜스포머로 들어갑니다. 여기서 사용하는 트랜스포머는 디코더 전용 트랜스포머 인데, Self-Attention 구조만을 사용합니다. 총 8층으로 되어있는 되어있는 트랜스포머의 출력으로 총 11개의 토큰이 생성됩니다. 여기에서 생성되는 11개의 토큰들은 Auto-Regressive하게 생성되지 않고 병렬적으로 생성됩니다.
- 6개의 이미지가 사용되기는 하지만, 어차피 연속적인 시간 흐름 아래에서 동일한 이미지가 오버랩되어 사용되기 때문에, 계산 결과를 저장해놓고 여러 번 사용해 불필요한 계산량을 줄일 수 있습니다.
트랜스포머의 출력으로 생성된 각 토큰들은 로봇의 행동을 결정하는 각 축으로 사용됩니다. 7개는 로봇 팔의 움직임(x, y, z, roll, pitch yaw, 그리퍼의 열림 정도), 3개는 로봇의 위치(x, y, yaw), 남은 한 개는 로봇의 행동 모드(로봇 팔 제어, 로봇 위치 제어, 에피소드 종료)를 결정합니다. 또, 각 축은 연속적인 공간이 아니라 256개의 구간으로 discrete화 됩니다. 때문에 모델의 손실 함수로 Cross-Entropy Loss가 사용됩니다. 그리고 트랜스포머를 학습할 때에는 모든 에피소드가 병렬적으로 투입되기 때문에, Causal Masking이 적용된 상태로 로봇의 출력이 생성됩니다.
Data
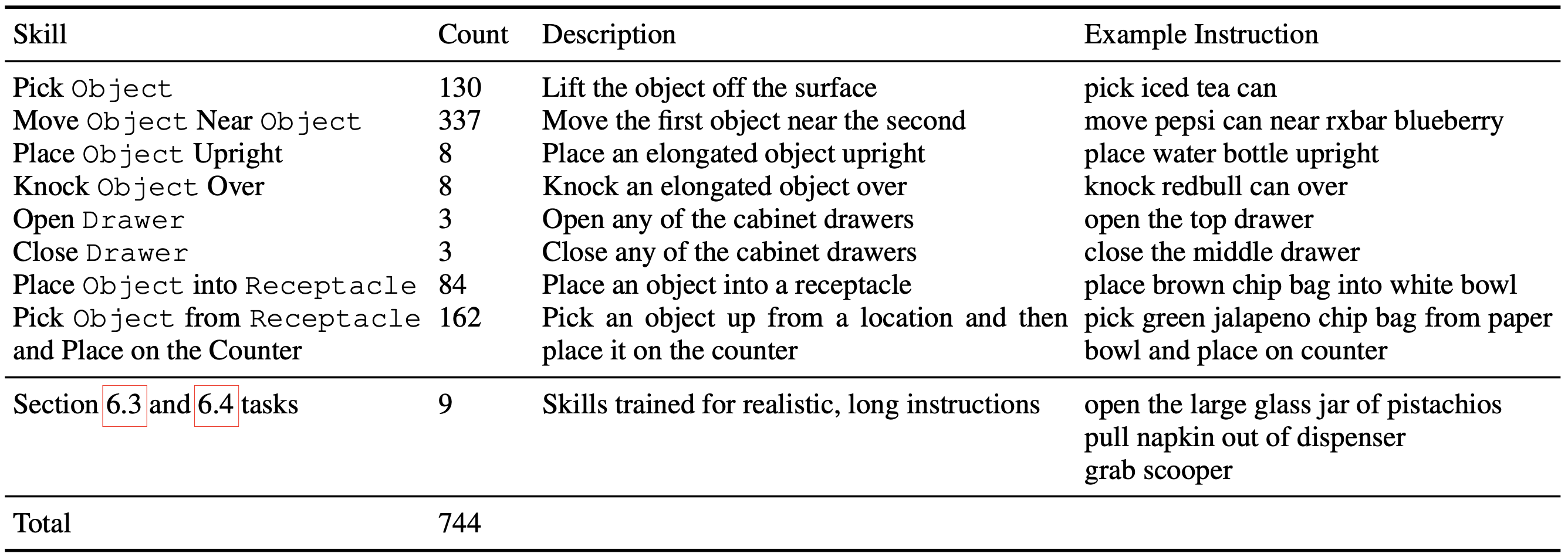
데이터의 구조는 위의 표와 같습니다. 데이터는 모델이 행하는 Skill의 종류에 따라 크게 구분되는데, Skill은 Verb와 Noun의 조합에 따라 위와 같이 총 8개의 종류가 존재합니다. 다양한 조합으로 모델을 학습시켜 모델이 일반화 성능을 습득할 수 있도록 합니다.

데이터는 위와 같이 주방을 모방한 공간에 Everyday Robot을 병렬배치할 수 있도록 해, 많은 데이터를 수집할 수 있도록 합니다. 이 공간에서 위의 Skill 분류에 해당하는 데이터들을 대량으로 생산합니다. 그리고 수집한 데이터를 바탕으로 모델을 학습할 때 사용합니다.

위 그림 중 (b)는 이전의 학습 데이터 수집 및 학습 환경과 유사한 주방입니다. 반면 (c)는 꽤 다른 부분이 있는 새로운 주방 환경입니다. (b) 환경을 Kitchen1, (c) 환경을 Kitchen2라고 명명합니다.
Experiment
실험에서는 기존에 굉장히 우수한 모델로 알려진 Gato와 BC-Z 등과 함께 RT-1 모델의 성능 제시합니다.
Seen & Unseen Task Performance

RT-1은 700개 이상의 지시문을 학습한 뒤, 이미 본 작업에 대해서는 97%라는 매우 높은 성공률을 보였으며, 학습 중 보지 못했던 지시문에 대해서도 76%를 달성했습니다. 또한 복잡한 방해 요소나 배경 변화 상황에서도 높은 성공률을 유지해, 새로운 작업, 물체, 환경에 대한 제로샷 문제 해결이 어느정도 가능함을 확인할 수 있습니다.
Realistic Generalization Performance (Skill)
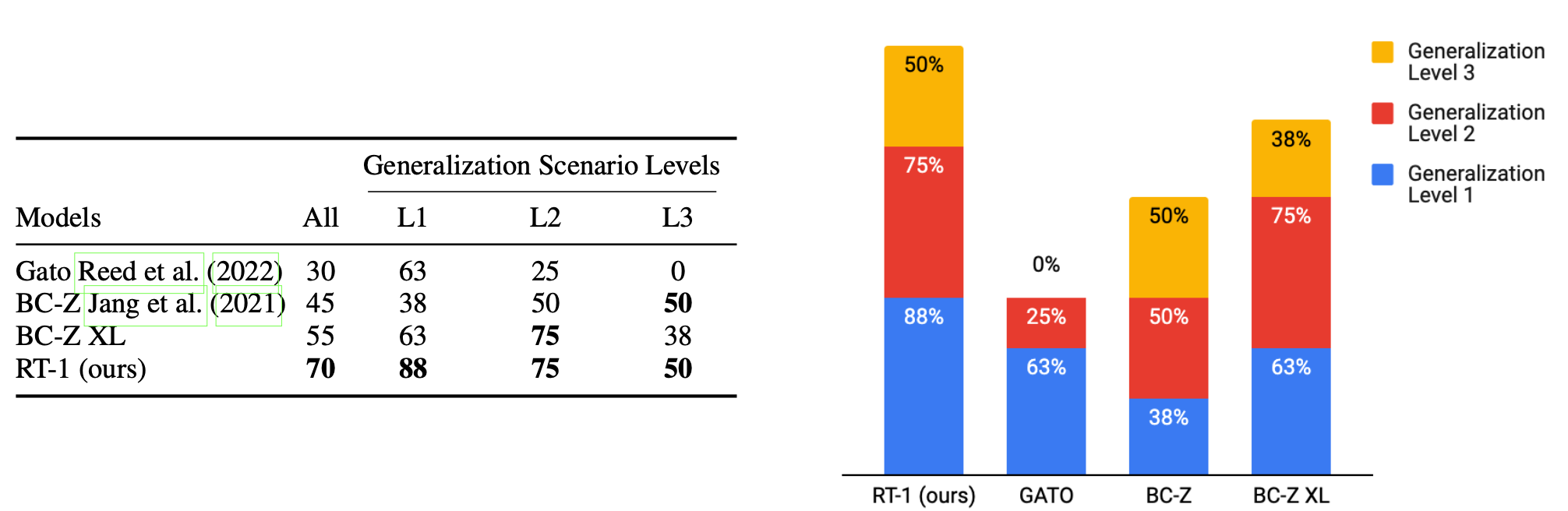
세 가지 수준의 Generalization 문제에서 RT-1과 Gato, BC-Z의 성능을 비교할 때, RT-1의 성능이 월등하게 뛰어난 것으로 나타납니다. 그러나 너무 완전히 새로운 환경(새로운 물체, 구조, 위치)에서는 여전히 잘 동작하지 못합니다.
Training with Additional Simulation Dataset
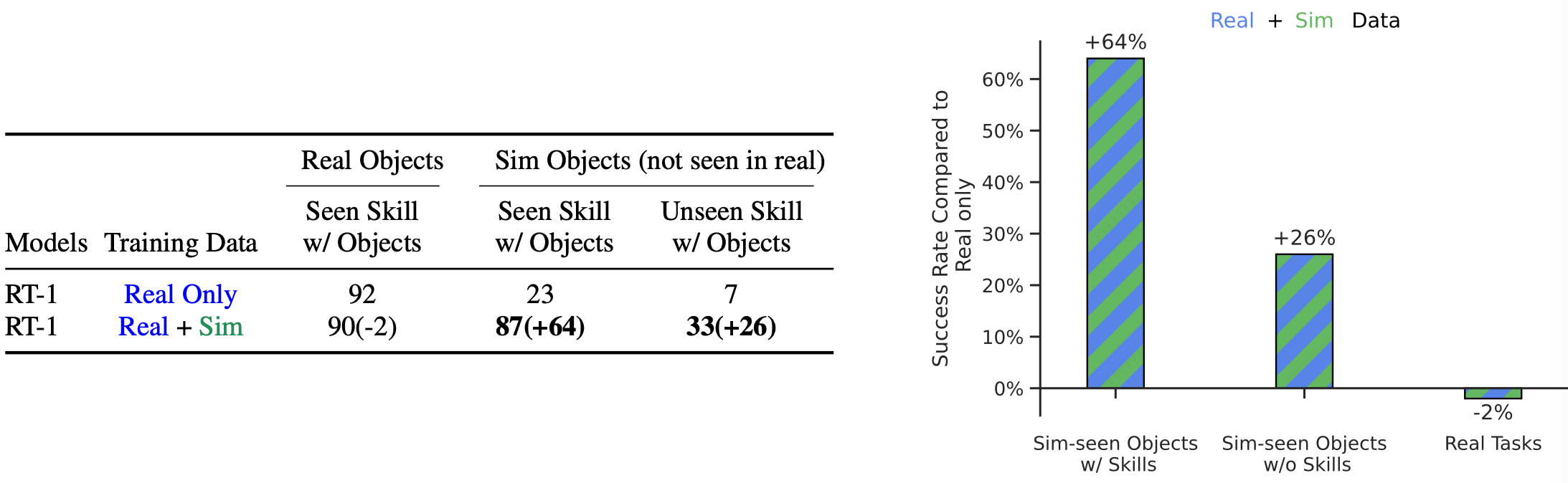
현실 데이터만으로 모델을 학습시킬 때와, 현실 데이터와 함께 시뮬레이션 데이터를 학습시킬 때의 성능을 비교합니다. 현실 데이터와 함께 시뮬레이션 데이터를 학습시킬 때, 현실 환경에서 이미 한 번 봤던 물체에 대해서는 오히려 성능이 소폭 감소합니다. 또한 시뮬레이션에서 마주한 완전히 새로운 작업에 대해서도 성능이 크게 향상됨을 확인할 수 있습니다. 즉, 현실 데이터와 함께 시뮬레이션 데이터를 학습시키면, 현실 작업 성능을 대체로 유지하면서도 시뮬레이션 환경에서의 전체적인 성능이 향상됩니다.
Training with Different Robot Datasets
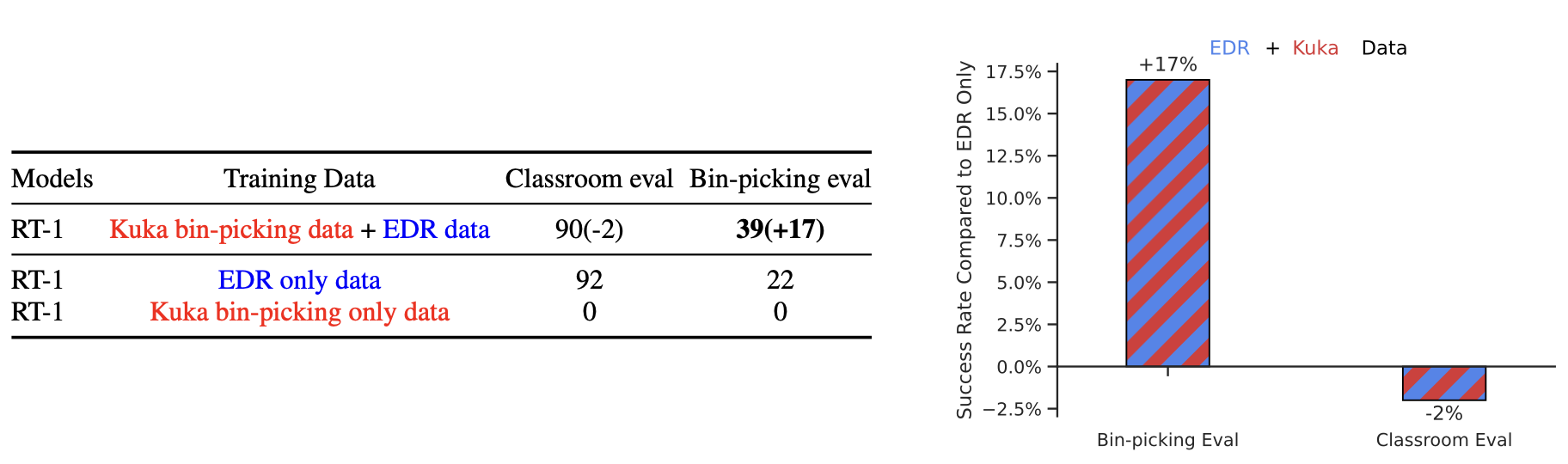
아예 다른 종류의 로봇(Kuka) 데이터를 추가로 학습시킬 때의 성능을 제시합니다. EDR(Everyday Robot)만으로 학습을 시키면, Classroom eval 작업에서 92%의 성능과 Bin-picking eval 작업에서 22%의 성능을 보입니다. 동일 태스크의 Kuka 로봇에서의 데이터를 추가로 학습시켰을 때, Classroom eval에서는 성능이 소폭 감소했으나, 원래도 좋은 성능을 보여주지 못했던 Bin-picking eval 작업에 대해서는 성능이 크게(+17) 향상되었습니다. 즉, 다른 종류의 로봇 데이터의 일반적인 패턴이 도움이 되기는 하지만, 이미 잘 하는 작업에 있어서는 오히려 편향으로 작용합니다.
Performance in a New Environment
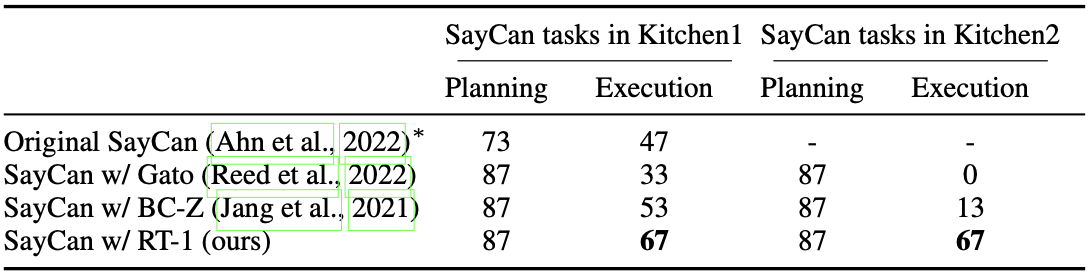
학습되지 않은 환경에서 RT-1 모델의 성능을 측정합니다. SayCan 평가 지표에서는 ‘계획을 올바르게 수립했는가(Planning)’와 ‘실제로 실행을 잘 수행했는가(Execution)’, 이 두 가지를 따로 평가합니다. RT-1의 경우 기존에 이미 학습한 Kitchen1 뿐만 아니라 새로운 환경인 Kitchen2에서도 67%의 Execution 높은 성공률을 보여줍니다.
Impact of data composition on performance
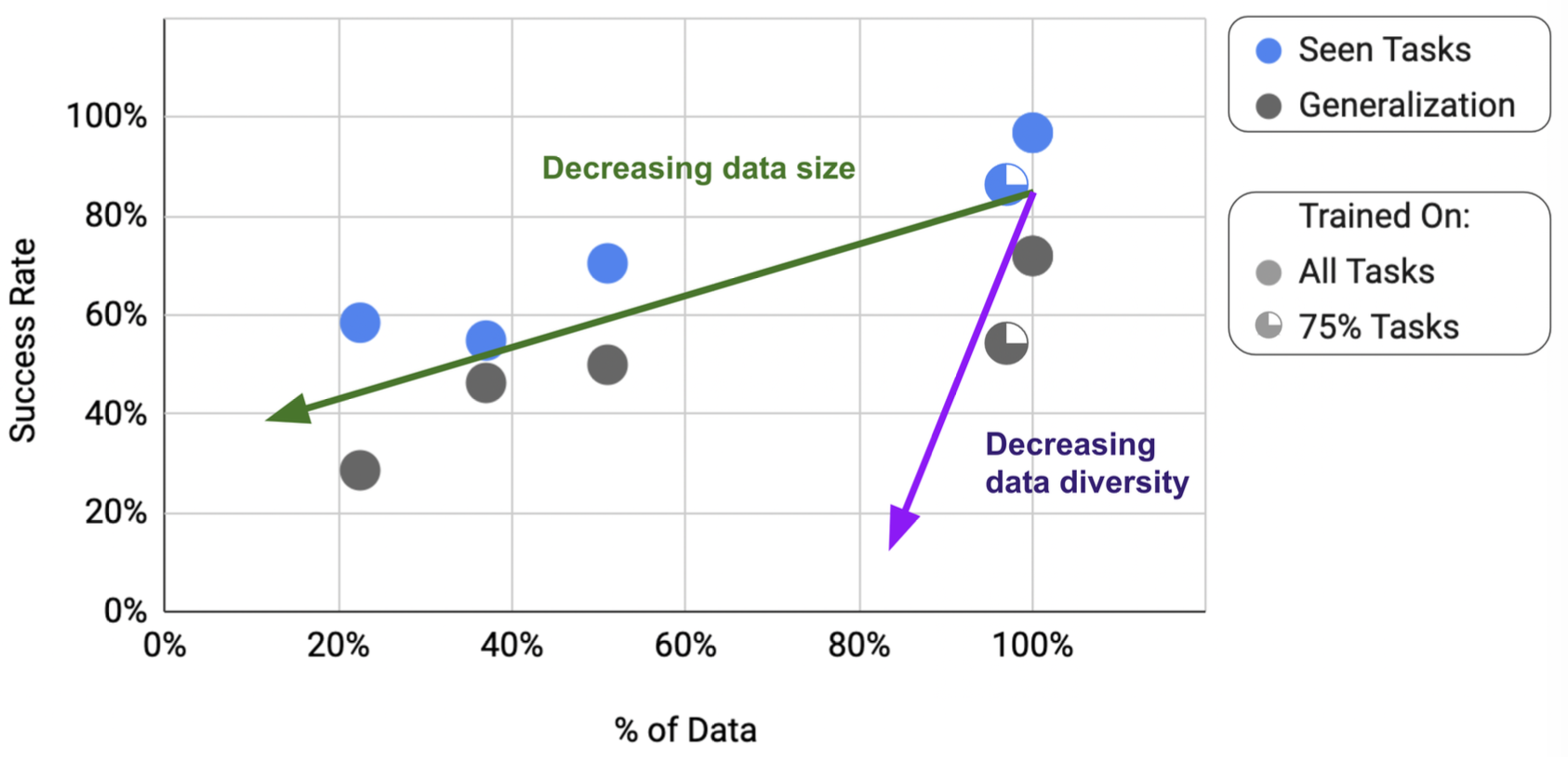
위는 데이터의 구성에 따른 성능 변화입니다. 데이터의 전체적인 양이 감소할 때, 모델의 성능은 당연히 점차적으로 감소합니다. 그런데, 데이터의 큰 비율을 차지하지 않는 몇 가지 종류의 태스크 종류를 배제시킬 때, 모델의 전체적인 성공 확률이 급격하게 감소하는 것으로 나타납니다. 즉, 다양한 태스크를 넓게 향상시키는 것이 모델의 일반화 성능에 큰 도움을 주는 것으로 보입니다.
Conclusions
RT-1은 새로운 구조와 대규모 데이터를 통해 새로운 태스크에 대한 일반화 성능을 크게 개선했습니다. 그럼에도 아래와 같은 몇 가지 한계점이 존재합니다.
- 모방 학습의 이론적 한계로 인해, 데모를 제공한 시연자의 성능을 뛰어넘는 성능을 발휘할 수 없습니다.
- 완전히 새로운 동작에 대한 일반화는 여전히 어렵습니다.
- 섬세하고 고난도의 조작은 수행할 수 없습니다.
댓글남기기