Prompt, Plan, Perform: LLM-based Humanoid Control via Quantized Imitation Learning
이 포스팅은 ‘Prompt, Plan, Perform: LLM-based Humanoid Control via Quantized Imitation Learning‘에 대한 내용을 담고 있습니다.
논문 주소: https://arxiv.org/pdf/2309.11359
Prompt, Plan, Perform: LLM-based Humanoid Control via Quantized Imitation Learning

휴머노이드 로봇을 제어하기 위한 다양한 시도가 있는데, 최근 대부분의 방법론들은 강화학습을 사용해 로봇을 제어합니다. 하지만 강화학습의 특성상 특정 태스크에 대해서 학습할 때에는 문제가 없지만, 이렇게 학습해놓은 강화학습 에이전트가 다른 일반적인 경우에 있어 광범위하게 상요되기는 어렵다는 단점이 있습니다. 대표적인 예시로 ASE(Adversarial Skill Embeddings)가 있는데요, 이 방법론에서는 고수준 정책과 저수준 정책을 분리해서 태스크를 해결합니다. 고수준 정책은 현재 내가 어떤 행동을 취해야하는지를 추상적으로 표현하는 잠재 벡터를 반환하고, 저수준 정책에서 이 잠재 백터를 받아 구체적인 행동을 결정하게 됩니다. ASE의 계층적인 구조가 기존의 강화학습 접근 방법에 비해 일반화 능력에서 유리하긴 하지만, 여전히 고수준 정책과 저수준 정책을 맞춘 상태에서 학습되기 때문에 다른 태스크에 일반적으로 적용시키기에는 여전히 어렵습니다.
이 논문에서는 위의 문제점을 해결하기 위해 GAIL(Generative Adversarial Imitation Learning) 프레임워크와 LLM을 함께 사용합니다. 고수준 정책을 일반화 능력이 뛰어난 LLM에게 결정해달라고 부탁하고, 그렇게 받은 고수준 정책을 바탕으로 PPO(Proximal Policy Optimization) 알고리즘으로 학습된 강화학습 에이전트가 구체적인 행동을 결정합니다.
Background
GAIL은 판별자(Discriminator)를 도입해 추가적인 보상신호를 제공함으로써 에이전트가 전문가의 행동을 모방하여 학습할 수 있도록 하는 프레임워크입니다.
\[\text{argmin}_\mathcal D - \mathbb E_{d^\mathcal M(s_t, a_t)}[\log(\mathcal D(s_t, a_t))] - \mathbb E_{d^\pi(s_t, a_t)}[\log(1-\mathcal D(s_t, a_t))]\]GAN에서 사용되는 판별자의 목적함수와 꼴이 거의 동일합니다. 위 목적함수를 통해 판별자는 학습되고, 또한 관련해서 추가적인 보상 신호를 제공합니다. 논문에서는 GAIL에서 조금 더 확장된 CALM 구조를 사용합니다.
Approach
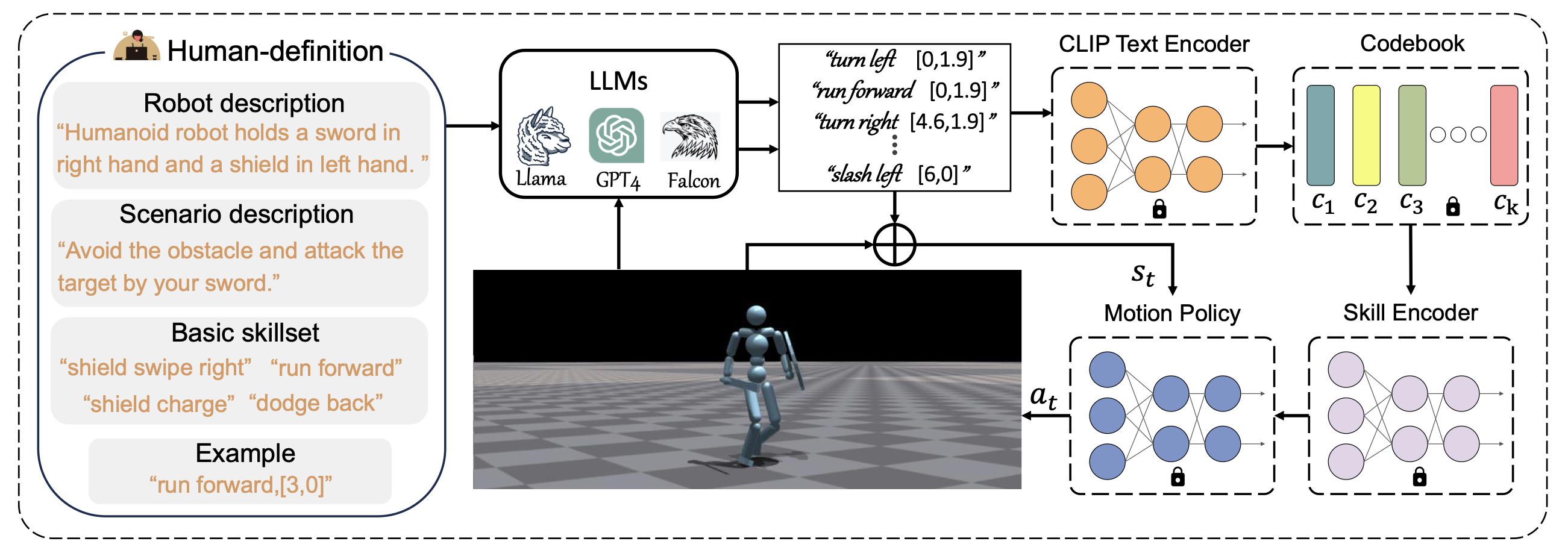
먼저 LLM에 위와 같이 Human-definition 꼴의 입력이 들어갑니다. 입력으로 로봇의 생김새, 작업 시나리오, 스킬 종류, 그리고 반환해야하는 출력 명령어의 포맷 예시가 들어갑니다. LLM이 출력으로 텍스트 명령어와 목표 좌표로 구성된 출력 명령어의 나열을 반환하게 되는데, 목표 좌표는 에이전트의 Observation 정보로 들어가게 되고, 텍스트 명령어는 조금의 가공을 더 거치게 됩니다.
\[\text{MSELoss} = \frac{1}{D}\sum^D_{i=1}(Enc_T(text) - Enc_T(label))^2\]텍스트 명령어는 Fine-Tuning된 CLIP(Contrastive Language-Image Pre-Training) Text Encoder를 통해 잠재벡터로 변환됩니다. CLIP은 위의 평균 제곱 오차 손실함수를 사용해 Fine-Tuning됩니다. 동일한 모션에 해당하는 다양한 텍스트 명령어가 있을텐데, 이 텍스트 명령어들이 해당되는 레이블을 인코딩해 얻은 잠재 벡터와 거리가 가까워지도록 해줍니다.
\[k = \text{argmin}_j ||f - e_j||\] \[f_d = \text{Codebook}(f) = e_k\] \[e_k = Enc_T(label_k)\]CLIP을 사용해 얻은 잠재 벡터를 바로 사용하는게 아니라, 그 잠재벡터와 가장 가까운 레이블 잠재벡터를 사용합니다. 코드북 기반으로 유한한 벡터 양자화를 수행해 경험해보지 못한 상황들을 보다 잘 처리할 수 있도록 합니다.
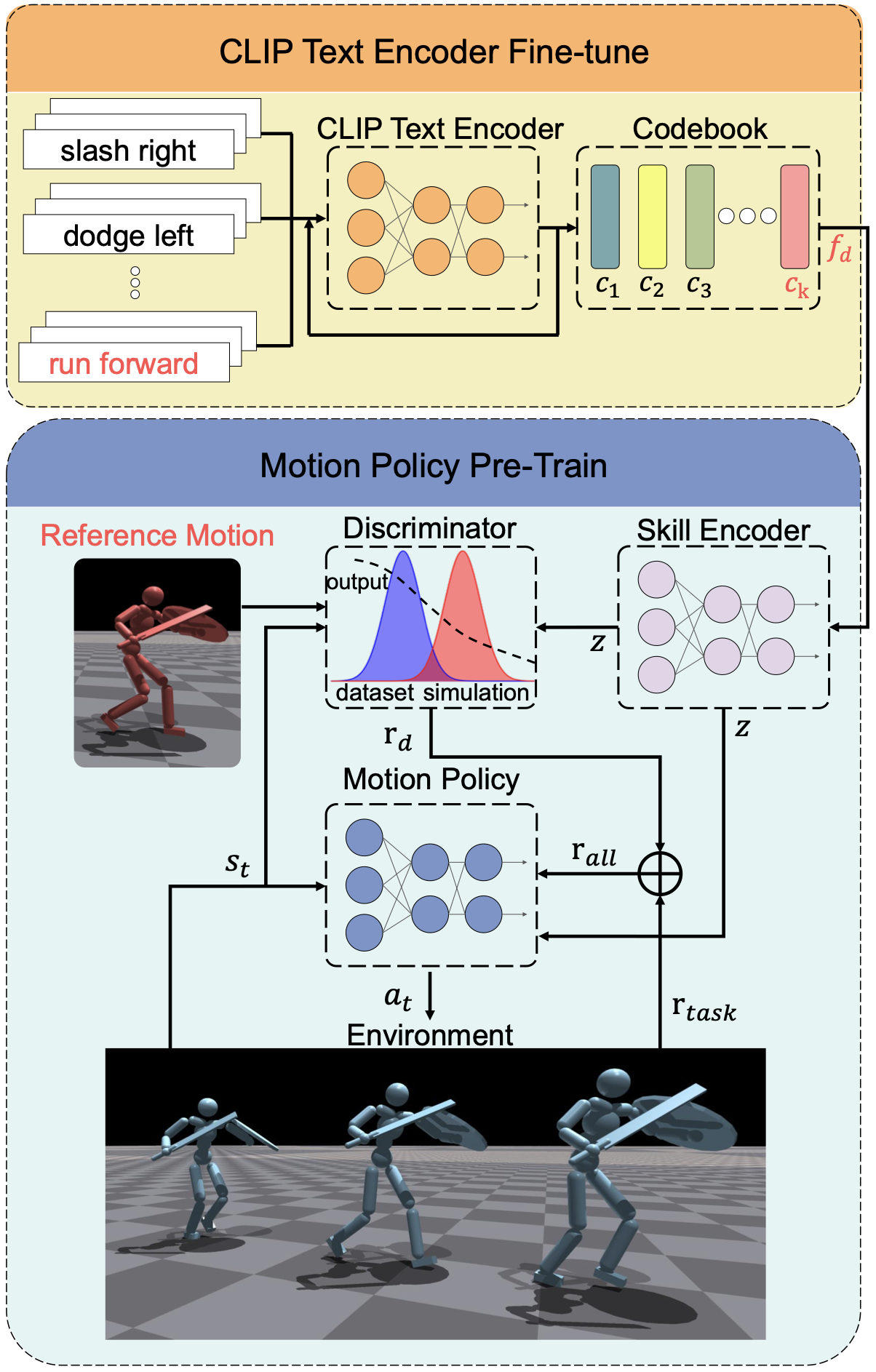
CLIP 단계에서 얻어진 잠재 벡터를 또 한 번 Skill Encoder를 통과시켜, 더 작은 잠재 벡터로 변환합니다. 이렇게 변환된 잠재벡터는 판별자에서 전문가 정책과 비교를 할 때 조건부로 사용됩니다.
\[\text{argmin}_\mathcal D - \mathbb E_{d^\mathcal M(s_t, s_{t+1})}[\log(\mathcal D(s_t, s_{t+1}\mid z))] - \mathbb E_{d^\pi(s_t, s_{t+1})}[\log(1-\mathcal D(s_t, s_{t+1}\mid z))]\] \[- \omega_{gp}\mathbb E_{d^\mathcal M(s_t, s_{t+1})}[|| \nabla_\alpha \mathcal D(\alpha) ||^2]\]이 논문에서 사용되는 판별자는 CALM(Conditional Adversarial Latent Models)을 기반으로 합니다. CALM은 GAIL보다 조금 더 일반화된 방법론이라고도 볼 수 있는데, GAIL에서 정의된 판별자는 전문가 데이터와 강화학습 에이전트가 생성한 데이터를 구분하는 방향으로 학습됩니다. 그런데 상태들의 나열만 제공되고 어떤 행동을 선택했는지 주어지지 않는 경우들도 더러 있는데, 이런 경우들을 다루기 위해서 위와 같이 행동이 아니라 그 다음 상태를 판별자의 입력으로 넣어줍니다. 그리고 계층적 구조를 사용하는 경우, 지금 에이전트가 선택해야하는 행동이 어떤 범주에 속하는 행동인지를 함께 제공됩니다. 따라서 이 정보가 판별자의 조건부로 함께 들어가게 됩니다.
\[r_d = \log(1-\mathcal D(s_t, s_{t+1} \mid z))\]그리고 위의 판별자 보상이 에이전트의 추가 보상으로 제공됩니다. 강화학습 에이전트는 PPO 알고리즘을 사용해 이전에 얻은 잠재 벡터와 타겟 좌표가 Observation으로 포함돼, 계속 새로운 행동을 생성합니다. 그리고 행동의 결과로 도달하게 되는 새로운 상태를 사용해 방금 에이전트의 행동이 전문가 행동과 유사한지 판별자에게 검사받는 과정이 계속 반복됩니다.
\[r_{task} = \omega_1 d_{root} \cdot d_t + \omega_2 d_{l} \cdot d_t + \omega_2 d_{r} \cdot d_t\] \[r_{all} = \omega_{task}r_{task} + \omega_{dis}\log(1 - \mathcal D(s_t, s_{t+1}\mid z))\]로봇이 전체 작업을 잘 수행하도록 하기 위해서 판별자 보상과 함께 목표 좌표로 움직이도록 하는 작업 보상을 같이 사용합니다. 작업 보상은 로봇의 루트와 왼쪽 엉덩이, 그리고 오른쪽 엉덩이의 방향과 목표 방향의 일치 정도에 의해 결정됩니다.
Experiments
휴머노이드 로봇을 대상으로 다양한 태스크에 대해 실험을 수행합니다. 데이터 수집과 훈련은 한 개의 A100 GPU를 사용하고 Isaac Gym에서 4096개의 환경을 병렬로 실행해 수행되었습니다. 강화학습 알고리즘으로는 PPO를 사용합니다.
Solve DownStream Tasks with LLMs Planner

먼저 LLM 플래너를 통해 다운스트림 태스크를 해결하는 문제에서, 저자들은 위와 같은 상황을 제시합니다. 설명하자면 앞에 피해야하는 빨간색 블록이 있고 그 뒤로 있는 목표를 로봇이 들고 있는 검으로 타격해야 하는 문제입니다. LLM 플래너를 사용한 경우 아래와 같은 행동 계획을 얻게 됩니다.
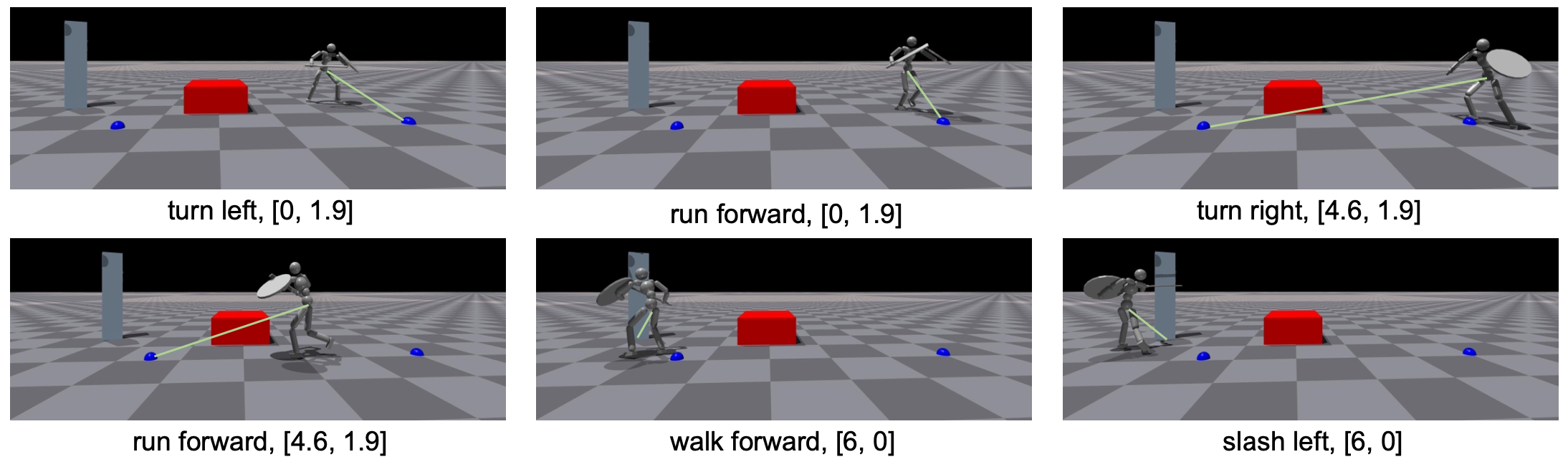
LLM 플래너에는 장애물의 위치, 및 기타 제약 조건들이 프롬프트로 들어갑니다. 또한 판별자에는 루트의 위치와 속도, 높이, 관절 속도, 몸체의 위치 정보가 제공됩니다.
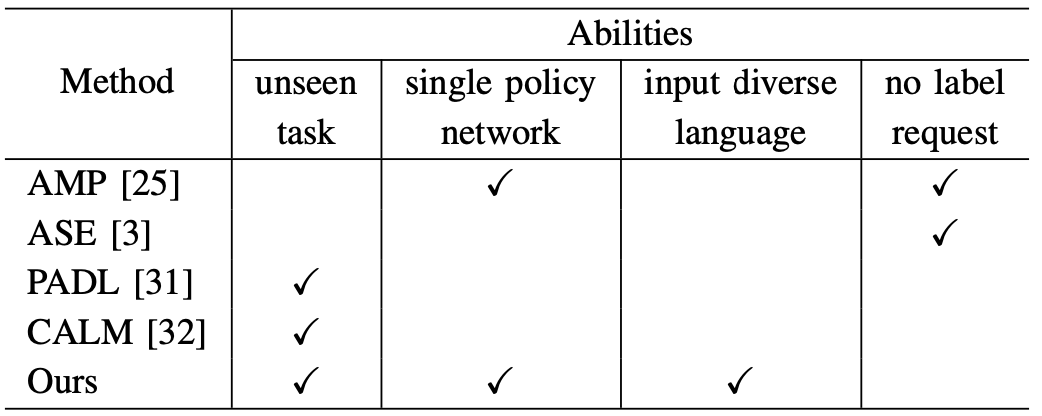
다른 기존 방법들과 비교했을 때, 이 논문에서 제안하는 방법은 경험해보지 못한 태스크에 대해서도 수행할 수 있는 능력이 있고, 단일 네트워크를 사용하고, 다양한 언어 입력을 처리할 수 있는 능력을 모두 가진다는 점에서 차별적입니다.
Evaluate Adaptive Language Encoder by Unseen Text

다음으로 사전학습된 텍스트 인코더와 코드북 벡터 양자화의 일반화 능력을 평가합니다. 훈련할 때 사용한 단어의 동의어로 텍스트 명령어를 사용했을 때, 이를 모델이 적절히 대처하는지를 확인합니다. 위의 표에서 CLIP을 미세 조정하기 이전에는 대부분의 모션의 정확도가 낮은데 반해, 미세 조정을 한 이후의 정확도는 크게 상승하는 것으로 나타납니다. 이를 통해 논문에서 제시하는 방법이 새로운 명령어를 처리할 수 있는 일반화 능력이 있음을 확인할 수 있습니다.
Comparison of General Task Rewards
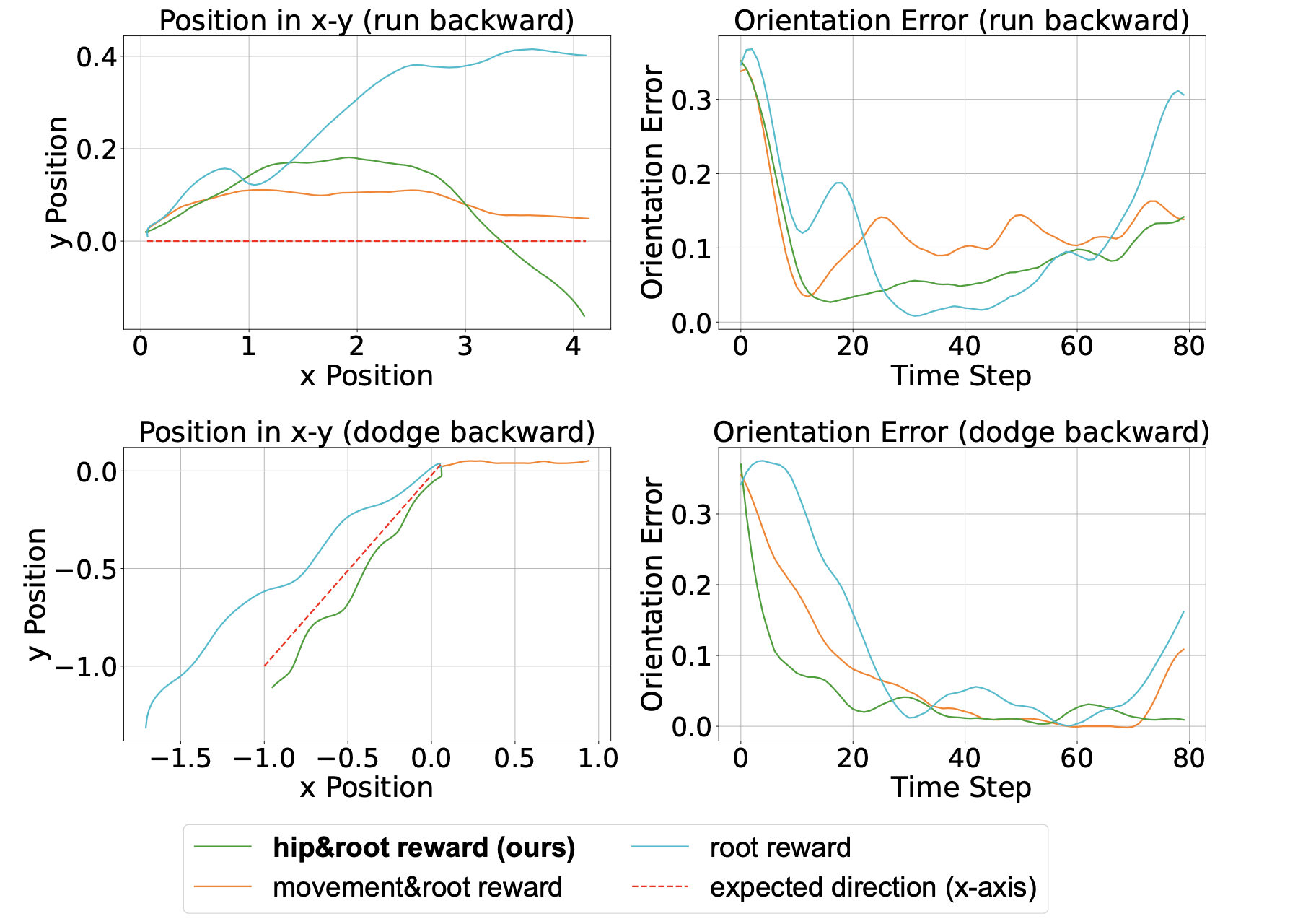
마지막으로 태스크 보상의 구성에 따른 차이를 살펴봅니다. 로봇의 루트 방향만을 고려하는 경우, 로봇의 이동 방향과 루트 방향을 고려하는 경우, 마지막으로 이 논문에서 채택한 로봇의 루트와 엉덩이 방향을 고려하는 경우를 살펴봅니다. 루트 방향만을 고려하는 경우 전진 움직임을 효과적으로 제어하지 못합니다. 루트 방향과 이동 방향을 고려하는 경우, 두 보상의 충돌로 인해 로봇이 원하는 방향으로 이동하지 못합니다. 로봇이 움직이지 않고 상체만 움직이는 태스크에서 특히 움직임 보상이 로봇을 계속해서 앞으로 움직이게 하는 문제점을 나타납니다. 논문에서 제시한 보상 설계 방식만이 모든 경우에서 원하는 방향으로 로봇이 움직이도록 합니다.
Conclusion
이 논문에서는 단일 적대적 모방 학습과 스킬을 계획하는 LLM을 결합하는 새로운 프레임워크를 제안합니다. 복잡한 태스크를 LLM을 통해 효과적으로 해결할 수 있음을 실험에서 확인하기는 했으나, 로봇 모델과 참조 모션 데이터가 상대적으로 이상적이라는 점에서 한계가 있습니다. 향후 연구로 더 실용적인 데이터를 생성하고 적용하는 방향을 제시합니다.
댓글남기기