컴퓨터시스템 06: 기계 수준 프로그래밍 4: 데이터
이 포스팅은 서울시립대학교 인공지능학과 백형부 교수님의 ‘컴퓨터시스템’ 강좌의 중간고사 이전 범위 수업 내용에 대한 정리를 담고 있습니다.
수업 자료 출처: Bryant and O’Hallaron, Computer Systems: A Programmer’s Perspective, 3rd Edition
기계 수준 프로그래밍 IV: 데이터
프로그램에서 데이터를 처리할 때, 배열과 구조체는 가장 기본적이고 중요한 데이터 구조입니다. 이러한 데이터 구조들이 어떻게 메모리에 저장되고, 어셈블리 언어에서는 이들을 어떻게 다루는지에 대해 살펴보겠습니다.
배열(Array)
C언어에서 배열은 일련의 동일한 타입의 데이터를 연속적으로 저장하는 자료 구조입니다. 배열의 각 요소는 인덱스로 참조되며, 인덱스는 0부터 시작합니다. C언어에서 배열과 관련된 기본적인 문법과 특징을 레퍼런스 중심으로 설명하겠습니다.
선언과 초기화

선언: 배열을 선언할 때는 타입, 배열의 이름, 그리고 대괄호 안에 배열의 크기를 명시합니다. 예: int val[5];
초기화: 배열을 선언함과 동시에 특정 값으로 초기화할 수 있습니다. 예: int val[5] = {1, 5, 2, 1, 3};
포인터
C언어의 독특한 문법들 중 하나인데요, 배열 이름은 배열의 첫 번째 요소의 주소를 나타내는 포인터로 사용될 수 있어, 배열과 포인터는 밀접하게 연관되어 있습니다. 예를 들어, int val[10]; 선언 후 int *p = val;로 p포인터에 val 배열의 시작 주소를 할당할 수 있습니다. 이후 *(p + 3)은 val[3]과 동일한 값을 참조합니다.
참조

배열의 특정 요소에 접근하려면 배열 이름과 인덱스를 사용합니다. 예: val[2]는 val 배열의 세 번째 요소를 참조합니다.
배열의 이름은 배열의 첫 번째 요소를 가리키는 포인터로 사용될 수 있습니다. 따라서, val[2]는 *(val + 2)와 동일합니다.
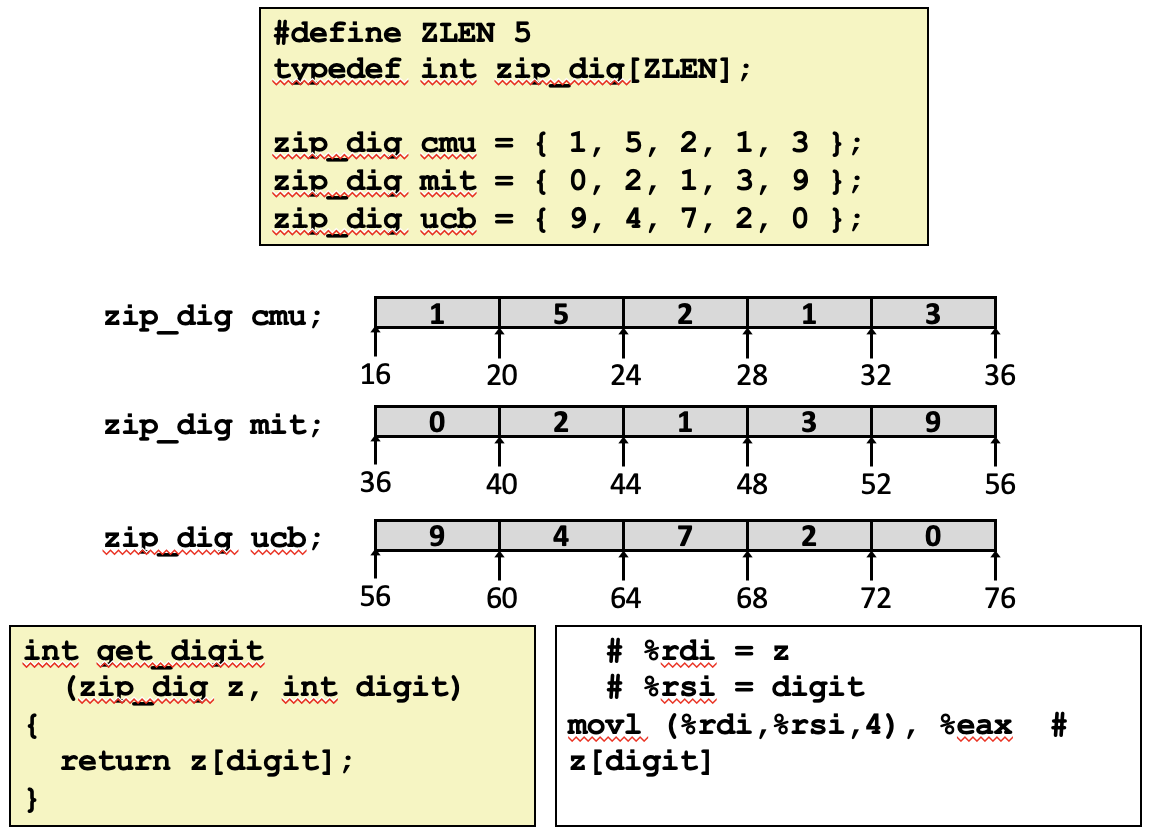
get_digit은 배열 내의 특정 값을 인덱스를 사용하여 참조하는 함수입니다. 어셈블리 언어에서 이 함수의 코드를 분석해보면, 완전 메모리 주소 지정 방식을 사용하여 주소 계산을 수행하는 것을 볼 수 있습니다. 구체적으로, %rdi에 저장된 주소에 %rsi에 저장된 인덱스 값을 4배 한 값을 더하여, 그 결과 주소에 위치한 값을 참조합니다. 정리하면, %rdi + 4 * %rsi에 해당하는 메모리 주소의 값을 읽어오는 작업을 수행한다고 할 수 있겠습니다.

이 예시에서는 배열의 모든 원소에 1을 더하는 작업을 수행합니다. 이 과정은 이전 예시와 매우 유사한 방식으로 진행됩니다.
Multi-demensional (Nested) Arrays
중첩 배열(Nested Arrays)은 배열 내에 또 다른 배열이 포함되어 있는 형태를 말합니다. 이런 구조는 다차원 데이터를 저장하고 관리하는 데 유용합니다. 가장 흔한 예로는 2차원 배열이 있으며, 이는 행렬(matrix)이나 테이블(table) 형태의 데이터를 표현할 때 사용됩니다.

예를 들어, T A[R][C];는 타입 T의 2차원 배열을 선언하는 방법입니다. 여기서 R은 행(row)의 수를, C는 열(column)의 수를 나타냅니다. 이 배열은 R개의 행과 C개의 열을 가진 그리드(grid)로 생각할 수 있으며, 각 셀(cell)에는 T 타입의 값이 저장됩니다.
int matrix[3][4];
이 코드는 int 타입의 값을 저장할 수 있는 3행 4열의 2차원 배열을 선언합니다. 이 배열의 각 원소는 matrix[i][j] 형태로 접근할 수 있으며, i는 행의 인덱스, j는 열의 인덱스를 나타냅니다.

중첩 배열의 원소들은 메모리 상에 연속적으로 배치됩니다. 예를 들어, 3행 4열의 배열을 선언하면, 총 12개의 원소가 메모리에 순서대로 일렬로 배치됩니다. 이러한 원소들이 연속적으로 배치된다는 사실을 통해, 배열의 첫 번째 주소만 알면, 특정 인덱스에 위치한 원소에 접근하는 것이 가능합니다.
중첩 배열 행 접근 코드 예시
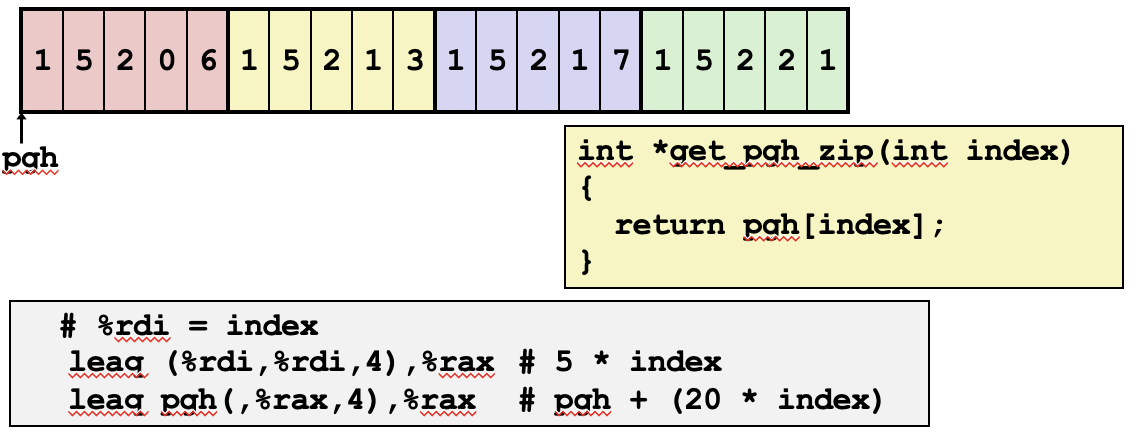
이 코드는 특정 인덱스에 해당하는 행의 첫 번째 주소를 반환하는 함수 get_pgh_zip의 구현입니다. C 언어에서 함수 선언 앞에 * 기호가 붙어있는 것으로 보아, 이 함수가 주소를 반환하는 것이 목적임을 알 수 있는데요, 구체적으로, 이 함수는 pgh 배열에서 해당 인덱스에 위치한 행의 첫 번째 주소를 찾아 반환합니다.
중첩 배열 원소 접근 코드 예시
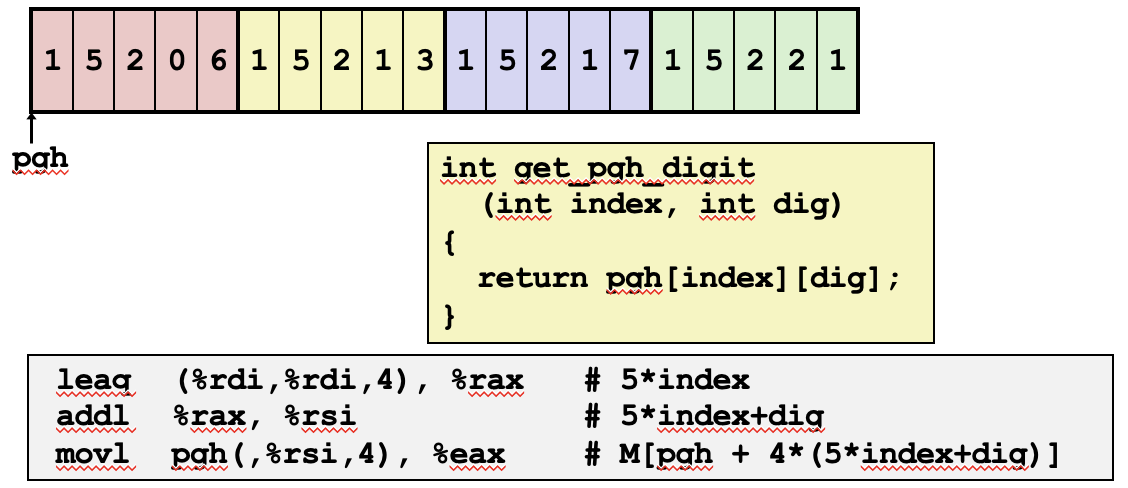
행 접근 코드를 이해하고 나면, 배열 내 특정 원소에 접근하는 것은 매우 간단합니다. 기본적으로 행의 주소를 계산한 후, 함수의 추가 파라미터로 받은 dig 값을 더하는 방식입니다. 이 과정에서 dig에 해당하는 열의 오프셋을 더하고, 해당 자료형의 크기(여기서는 4바이트)를 곱하여 최종 주소를 계산합니다. 이렇게 하면 원하는 원소에 정확히 접근할 수 있습니다.
-
leaq (%rdi,%rdi,4), %rax- 이 명령어는index * 5를 계산합니다. 이는 특정 행에 대한 오프셋을 구하기 위한 계산입니다. -
addl %rax, %rsi- 계산된 행의 오프셋에dig값을 더합니다.dig는 추가적으로 함수에 전달된 파라미터로, 특정 열에 접근하기 위한 값입니다. 이로써5 * index + dig의 결과를 얻게 됩니다. -
movl pgh(,%rsi,4), %eax- 마지막으로,pgh배열에서 계산된 위치의 원소를 메모리에서 읽어옵니다. 여기서%rsi에 4를 곱하는 이유는 각 원소가 4바이트 크기를 가지기 때문입니다. 즉,pgh + 4 * (5 * index + dig)위치의 주소에 해당하는 값을%eax에 저장합니다.
Multi-Level Array
다중 레벨 배열(multilevel array)은 주소의 배열로 이해할 수 있습니다. 이 구조는 데이터를 계층적으로 구성하는 데 유용하며, 이를 통해 복잡한 데이터 구조를 효율적으로 관리할 수 있습니다. 다음 예시를 통해 설명하겠습니다.
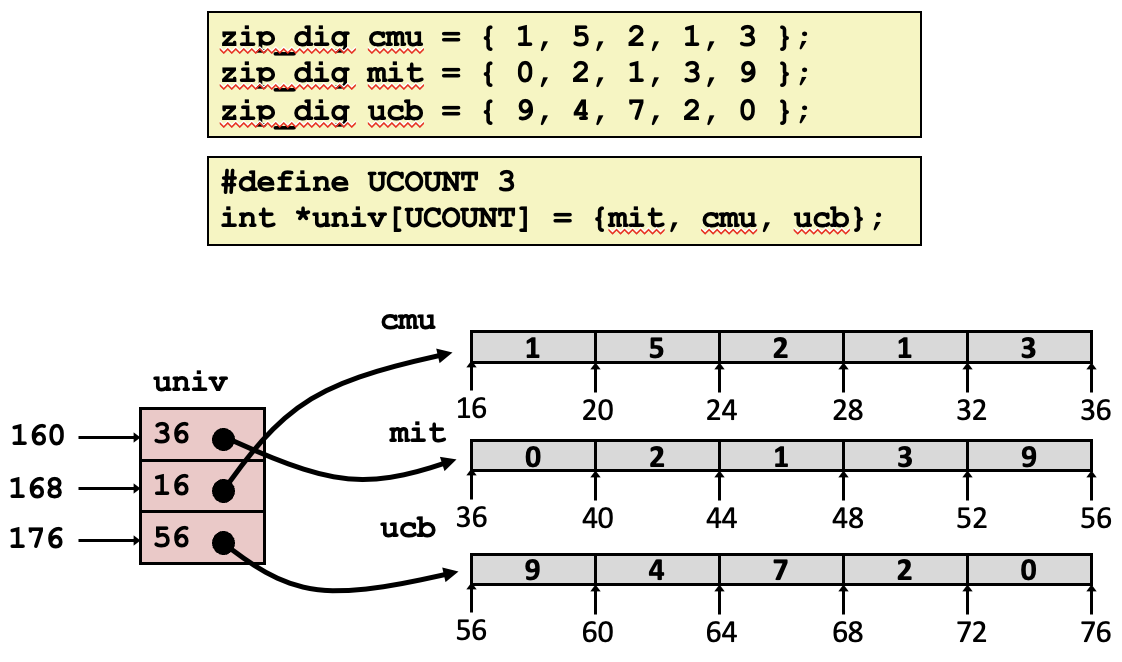
예시에서는 세 개의 대학교(CMU, MIT, UCB)의 우편번호를 나타내는 배열이 정의되어 있습니다. 각 대학교의 우편번호는 정수 배열로 표현되며, 각 배열에는 우편번호를 구성하는 숫자들이 순서대로 저장되어 있습니다.
UCOUNT는 배열 univ의 크기를 정의하는 매크로로, 여기서는 3입니다. 이는 univ 배열이 세 개의 요소를 가지고 있음을 의미하며, 각 요소는 mit, cmu, ucb 배열의 주소를 가리키는 포인터입니다
다중 레벨 배열 원소 접근 코드 예시
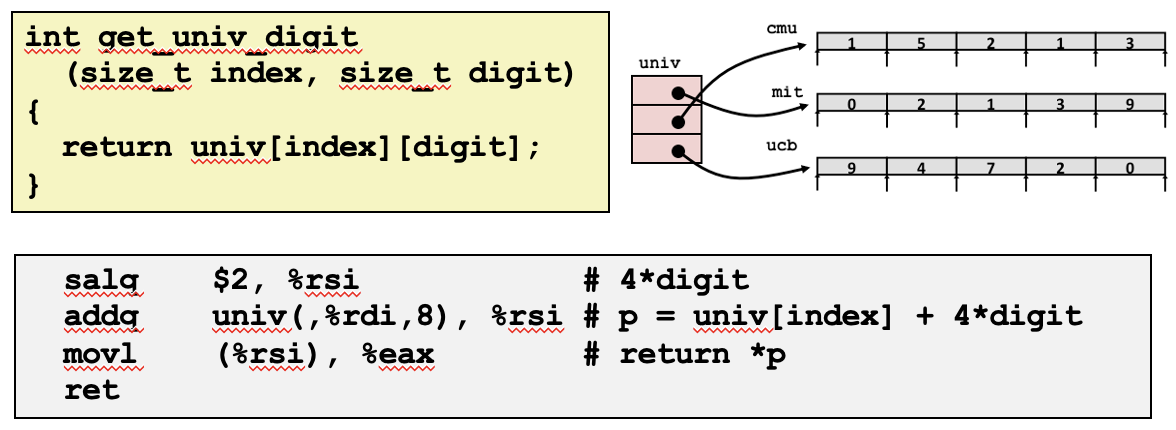
위 코드는 64비트 운영 체제에서 다중 레벨 배열 내 특정 원소에 접근하는 방법을 설명합니다. 이는 각 대학교의 ZIP 코드 숫자를 가리키는 포인터 배열을 활용하는 방식으로, 특정 대학의 특정 숫자에 접근하기 위한 절차를 보여줍니다. 중첩 배열에 비해 다중 레벨 배열을 사용하면 약간의 차이가 있으며, 이 경우 특히 이중 참조가 필요합니다.
구조체(Sturtures)
구조체(structure)는 C 언어에서 서로 다른 자료형을 하나의 논리적 단위로 묶기 위해 사용하는 사용자 정의 데이터 타입입니다. 구조체를 사용함으로써 관련된 데이터를 모아서 효율적인 데이터 관리가 가능해지며, 코드의 가독성과 유지보수성이 향상됩니다.
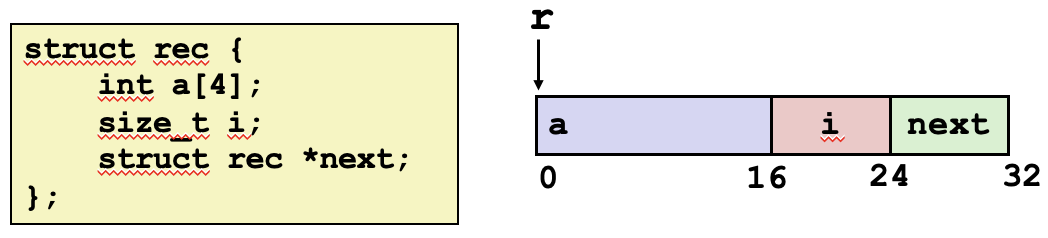
구조체는 다양한 자료형의 변수들을 포함할 수 있으며, 이러한 변수들을 필드(field) 또는 멤버(member)라고 합니다. 구조체는 다양한 자료형의 조합으로 구성될 수 있는데요, 이를 통해 복잡한 데이터 구조를 표현할 수 있습니다.
구조체를 사용하여 변수를 선언할 때, 변수들을 더 컴팩트하게 저장할 수 있는 방법이 있음에도 불구하고, 선언된 순서를 유지합니다. 이는 구조체 내의 데이터가 논리적으로 관련되어 있고, 코드의 가독성과 유지보수성을 향상시키기 때문입니다.

get_ap 함수는 rec 구조체의 포인터 r과 배열 인덱스 idx를 매개변수로 받습니다. 이 함수는 r이 가리키는 구조체 내 배열 a의 idx 인덱스에 해당하는 원소의 주소를 반환합니다. 반환 타입은 int*입니다, 즉 정수형의 포인터입니다.
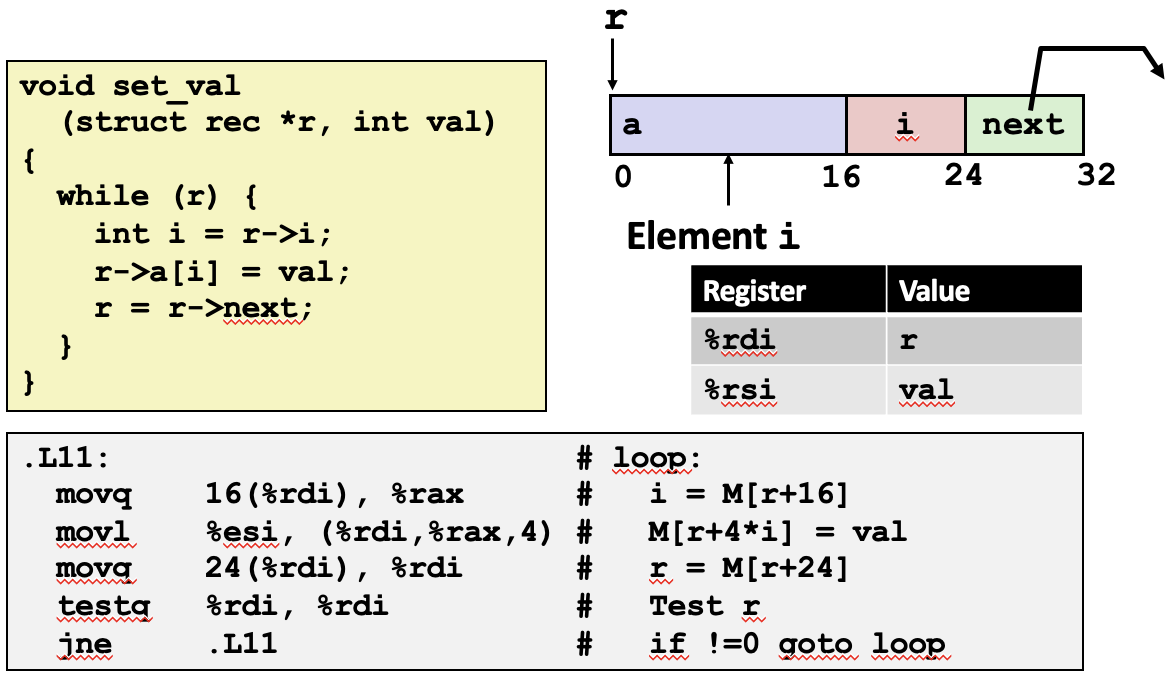
set_val 함수는 rec 구조체의 포인터 r과 정수 val을 매개변수로 받습니다. 이 함수는 연결 리스트를 순회하면서, 각 노드의 a 배열에서 인덱스 i 위치에 val 값을 할당합니다. 순회는 next 포인터를 사용하여 다음 노드로 이동하면서 수행되며, next가 NULL일 때까지 계속됩니다.
필드 배정 규칙
구조체의 메모리 정렬(alignment)은 효율적인 메모리 접근을 위해 중요합니다. 컴퓨터 아키텍처가 효율적으로 데이터를 읽고 쓰기 위해서는, 이러한 데이터가 특정 정렬 규칙에 따라 메모리에 배치되어야 합니다. 이 규칙은 데이터 타입에 따라 다르며, 일반적으로 데이터 타입의 크기에 기반을 둡니다. 여기서는 구조체 필드의 정렬 규칙에 대해 설명하겠습니다.
스트럭쳐 필드의 메모리 정렬 규칙
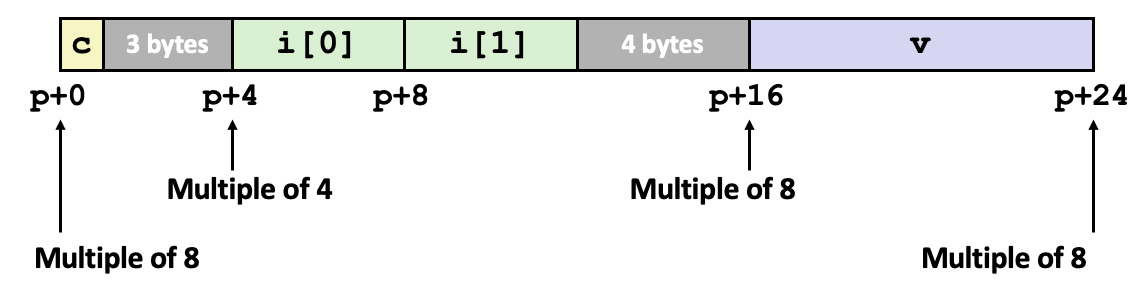
-
기본 정렬 규칙
각 필드는 그 타입의 크기에 맞추어 정렬됩니다. 예를 들어,
char타입은 1바이트 크기이므로 어떤 주소에도 배치될 수 있습니다(1의 배수). 반면에, 4바이트 크기인int타입은 4의 배수인 주소에 배정되어야 합니다. -
구조체 자체의 정렬
구조체 전체도 가장 큰 필드의 배수에 맞추어 정렬됩니다. 예를 들어, 구조체가
char,int,short타입 필드를 가지고 있다면, 가장 큰 타입인int가 4바이트이므로 구조체 전체도 4의 배수 주소에 배치됩니다. -
패딩(Padding)
필드 사이에는 메모리 정렬을 유지하기 위해 필요하지 않은 메모리 공간(패딩)이 삽입될 수 있습니다. 예를 들어,
char다음에int가 오는 경우,char는 1바이트만 사용하지만,int가 4의 배수 주소에 배정되도록 3바이트의 패딩이 추가될 수 있습니다.
이러한 정렬 규칙은 메모리 접근 속도를 최적화하고, 일부 아키텍처에서는 정렬되지 않은 메모리 접근이 에러를 발생시킬 수 있기 때문에 중요합니다.
구조체 배열
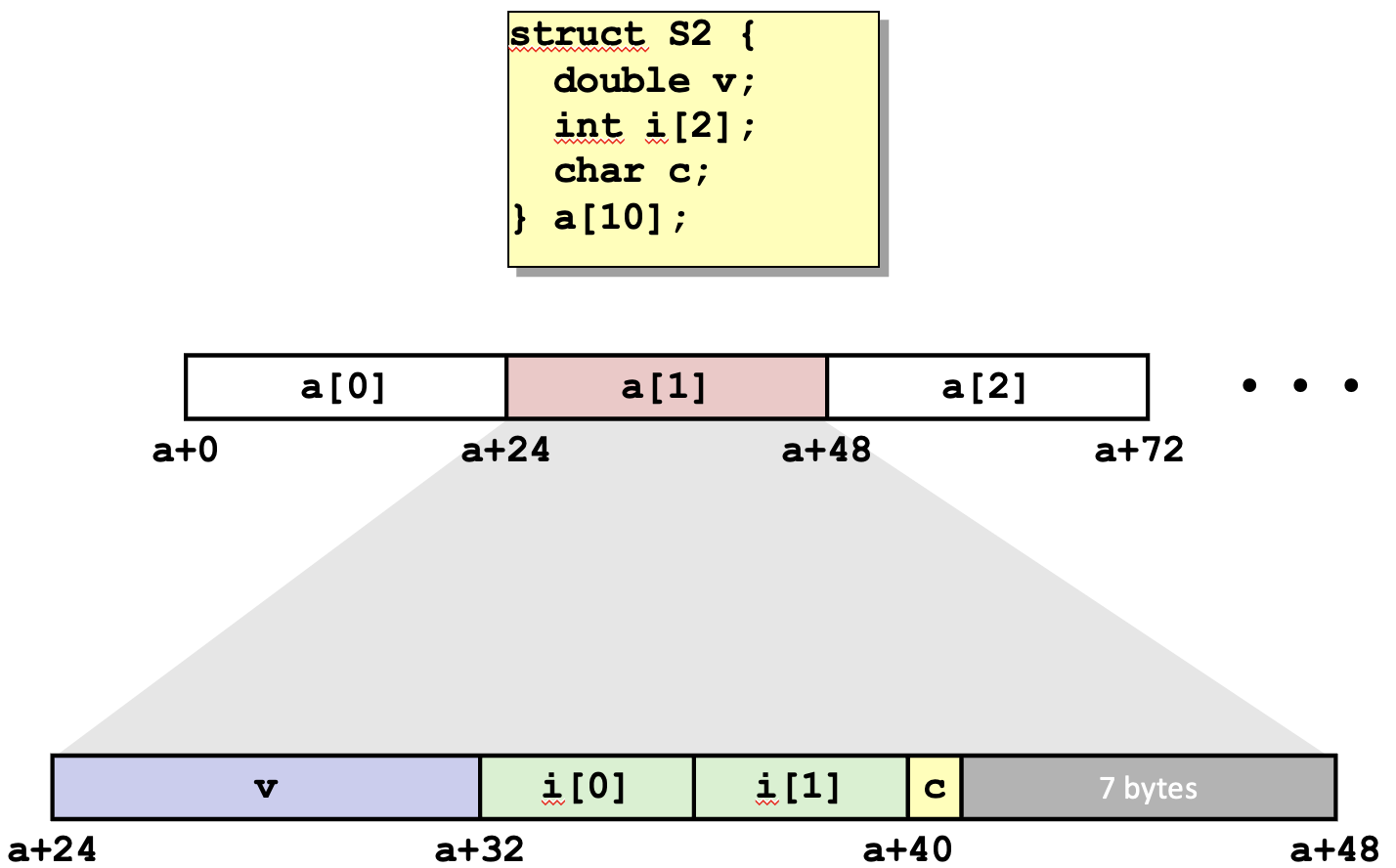
struct S2 { double v; int i[2]; char c; } a[10];는 S2라는 구조체 타입을 정의하고, 이 타입을 갖는 a라는 이름의 배열을 선언하는 코드입니다. 이 배열은 struct S2 타입의 객체를 10개 저장할 수 있습니다.
메모리 정렬과 패딩에 대해서 주의해야 합니다. 구조체의 메모리 정렬은 가장 큰 필드의 크기에 의해 결정됩니다. 이 경우, double 타입의 v가 가장 큰 필드이므로, struct S2는 8바이트 경계에서 정렬됩니다. char c; 필드 다음에는 다음 구조체 인스턴스가 8바이트 경계에 정렬되도록 메모리 패딩이 추가됩니다. 따라서 각 struct S2 인스턴스의 실제 메모리 크기는 필드의 크기 합보다 크게 됩니다.
a 배열을 사용하여 각 구조체 인스턴스의 필드에 접근할 수 있습니다. 예를 들어, a[0].v는 배열의 첫 번째 S2 구조체 인스턴스의 v 필드에 접근하고, a[1].i[1]는 배열의 두 번째 S2 구조체 인스턴스의 i 배열의 두 번째 원소에 접근하는 방법입니다.
공간 절약
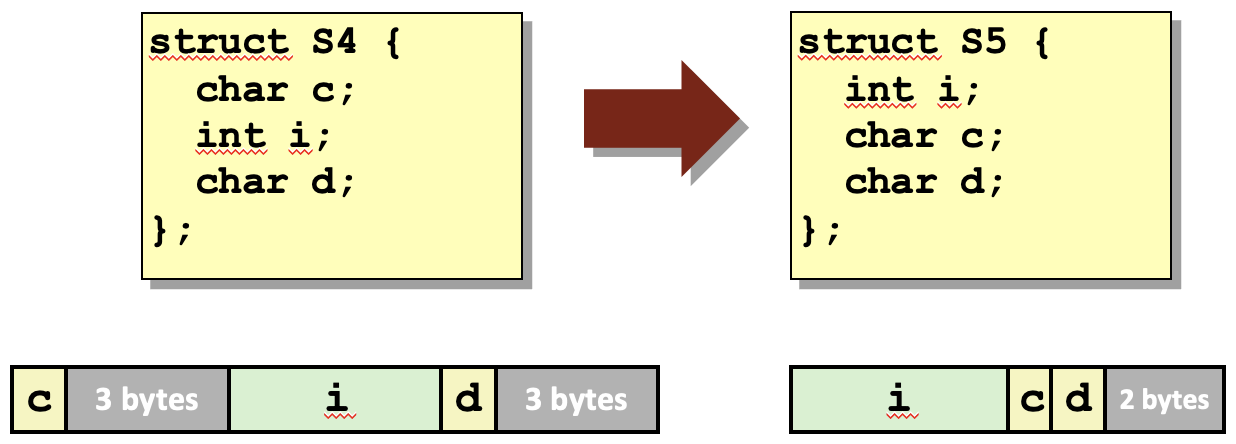
C언어에서 구조체를 선언할 때, 필드를 더 메모리 효율적으로 배치할 수 있는 순서가 있음에도 불구하고, 컴파일러는 이러한 순서로 자동으로 필드를 재배치하지 않습니다. 따라서, 프로그램 작성자는 메모리 사용을 최적화하기 위해 스스로 필드의 순서를 조정해야 합니다..
댓글남기기